W poprzednim numerze APA wytłumaczone zostało z jakich elementów składają się programy VI i jak tworzy się panele, diagramy oraz obiekty złożone z podprogramów. Omówione zostały także kwestie struktur sekwencyjnych i instrukcji warunkowych. Kontynuując ten temat w obecnym numerze, zajmiemy się bardziej zaawansowanymi konstrukcjami dostępnymi podczas tworzenia diagramów, które pozwalają na konstruowanie pętli, formuł obliczeniowych oraz zmiennych programowych.
Pętle programowe
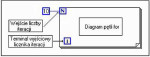
Jednymi z wręcz nieodzownych struktur, potrzebnych podczas programowania są pętle, pomocne przy wielokrotnym powtarzaniu cyklicznych operacji. W programie LabVIEW zaimplementowano dwie pętle – for i while. Konstrukcję pętli for stosuje się wtedy, gdy liczba wymaganych powtórzeń jest znana w danym miejscu programu. W języku G pętla for ma postać ramki (rys. 1) obejmującej poddiagram stanowiący blok kodu programu, który ma być wykonany określoną liczbę razy. Ramka ta ma predefiniowane wejście liczby iteracji oraz terminal wyjścia licznika powtórzeń, którego wartość zmienia się w zakresie od 0 do N-1, gdzie N to wejście liczby iteracji podane w formacie long integer. Dołączenie danej zmiennoprzecinkowej do wejścia liczby iteracji spowoduje zaokrąglenie tej liczby do wartości całkowitej. Licznik iteracji jest zerowany w momencie rozpoczęcia działania pętli i inkrementowany po każdej z nich. Sprawdzenie warunku zakończenia jest wykonywane przed rozpoczęciem każdej kolejnej iteracji, dlatego dla N=0 pętla nie wykona ani razu swojego diagramu i zakończy działanie.
|
LabVIEW Touch Panel Module |
Druga ze stosowanych w LabVIEW pętli nazywa się while i używa się jej wówczas, gdy liczba wymaganych powtórzeń wykonania nie jest znana. Pętla while także ma postać ramki obejmującej diagram (rys. 2) stanowiący blok kodu programu, którego wykonanie jest powtarzane. Ramka ta ma predefiniowany terminal wyjścia licznika iteracji oraz terminal warunku kontynuowania działania pętli. Terminal kontynuacji działania pętli korzysta z wartości boolowskich wypracowanych przez diagram pętli. Konfiguracja terminala kontynuacji pozwala ustalić wartość logiczną przerywającą lub też konieczną do kontynuowania działania pętli. Zasady te oznaczone są odpowiednio jako Stop if True lub Continue if True. Sprawdzenie warunku zakończenia jest realizowane po każdej iteracji, dlatego zawsze wykonywana jest przynajmniej jedna iteracja pętli. Działanie tej pętli jest analogiczne do pętli „do...while” języka C.
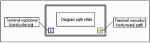
Rys. 2. Diagram pętli while
|

Rys. 3. Struktury LabVIEW z terminalami wejściowymi
|
Rys. 4. Diagram z wejściem tablicowym z autoindeksacją
|
W obu zaimplementowanych pętlach, każda iteracja polega na wykonaniu bloku objętego ramką konstrukcji pętlowej. Blok kodu może być pojedynczym diagramem lub zestawem niezależnych poddiagramów, ale bez przepływu danych pomiędzy nimi. Takie niezależne poddiagramy będą wykonywane w ramach pętli równolegle – jeden raz w każdej iteracji. Jeżeli w którymś z poddiagramów znajdują się także pętle, nazywane wtedy pętlami zagnieżdżonymi, to kolejne iteracje pętli zewnętrznej rozpoczną się po wykonaniu pętli zagnieżdżonej. Czas realizacji poddiagramów z pętlami może być dosyć długi i wówczas, gdy pozostałe diagramy wykonają swoje zadanie, to pozostają zawieszone aż do momentu rozpoczęcia nowej iteracji przez pętlę zewnętrzną. W związku z powyższym, odpowiednia konstrukcja diagramów, jak też ich rozmieszczenie wewnątrz tych samych lub osobnych pętli może mieć duży wpływ na kolejność wykonywania poszczególnych działań, co może mieć znaczenie dla użytkownika z różnych, zależnych od danego układu pomiarowego powodów.
Konstrukcje pętli for i while mogą mieć wejścia i wyjścia danych. Tunel wejściowy danych tworzy się automatycznie w momencie prowadzenia połączenia pomiędzy wejściem węzła znajdującego się na zewnątrz pętli, a wejściem węzła poddiagramu pętli. Podobnie tunel wyjścia danych powstaje podczas łączenia wyjścia węzła poddiagramu pętli z wejściem węzła znajdującego się poza strukturą. Działanie pętli rozpoczyna się po otrzymania wszystkich danych wejściowych, których to wartości są zapamiętane i przekazywane do kolejnych iteracji pętli. Oznacza to, że jeśli do tunelu wejściowego pętli dołączony jest terminal obiektu nastawczego, to pętla będzie dysponować jego stanem uzyskanym w momencie rozpoczęcia swojego działania. Zmiany stanu tego obiektu nastawczego w czasie działania pętli nie są w niej zauważane. Jeśli pętla ma reagować na aktualny stan obiektu nastawczego, to jego terminal musi być umieszczony wewnątrz struktury pętli. Możliwe jest także przekazywanie danych wejściowych w postaci tablicy. Realizowane jest to na dwa sposoby: albo zwyczajnie – cała tablica przekazywana jest na raz i utrzymywana w pamięci w czasie trwania pętli (opcja Disable Indexing), albo też wykorzystując indeksowanie (rys. 4), aby w kolejnych iteracjach dostępne były tylko te dane, których indeksy tablicy odpowiadają numerowi aktualnej iteracji (opcja Enable Indexing). W przypadku tablicy wielowymiarowych, kolejne iteracje dostają jako dane wejściowe kolejne podtablice. Jednocześnie skorzystanie z auto-indeksowania wpływa na liczbę iteracji pętli for, która to liczba jest wtedy określona przez mniejszą z dwóch wartości – wejściowej liczby iteracji lub rozmiaru tablicy z danymi. Ponadto, w sytuacji tej wejście liczby iteracji może zostać niepołączone. W przypadku kilku wejść z auto-indeksowaniem, liczba iteracji jest określana rozmiarem najmniejszej tablicy. Wpływ auto-indeksowania na pętlę while jest podobny, z wyjątkiem, gdy rozmiar tablicy jest mniejszy niż liczba powtórzeń wynikająca z działania algorytmu, dane podawane w kolejnych iteracjach przyjmują wartości domyślne dla danego typu liczb. Dla tablicy double są to zerowe wartości numeryczne.
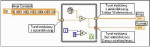
Dane wyjściowe są generowane po zakończeniu działania pętli. Tunel wyjściowy struktur for i while może pracować z auto-indeksacją lub bez niej, niezależnie od rodzaju danych doprowadzonych z wnętrza pętli (rys. 5). Jeśli pracuje bez auto-indeksacji, dostarcza wartość wyprowadzoną na wyjście dopiero podczas ostatniej iteracji pętli. Natomiast w trybie auto-indeksacji tworzona jest na wyjściu tablica z danymi dostarczonymi po każdym powtórzeniu pętli. Liczba wymiarów tablicy wyjściowej zależy od rozmiaru danych produkowanych w iteracjach.
Powyższe zasady dotyczące działania pętli są przyczyną pewnych zależności związanych z wydajnością operacji tablicowych. Okazuje się bowiem, że pętle for są wydajniejsze od pętli while, co wynika ze z góry znanej liczby powtórzeń. Dzieje się tak, gdyż w przypadku, gdy liczba iteracji przekroczy rozmiar tablicy z danymi, aplikacja musi realokować pamięć i przenieść dane do nowego obszaru, co skutkuje dodatkowym obciążeniem układów procesora i pamięci. Niemniej, pętle while mogą być znacznie wygodniejsze do realizowania niektórych algorytmów. Warto zwrócić uwagę, że pętle for są domyślnie ustawione w trybie auto-indeksacji zarówno wejść – jeśli te są tablicami, jak i dla dowolnego typu wyjść. Pętle while domyślnie pracują bez tego trybu.
Rejestry przesuwne
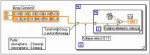
Opisane powyżej pętle nie mogą być w pełni użyteczne, bez możliwości przenoszenia danych pomiędzy kolejnymi iteracjami. Aby tego dokonać, zaimplementowana została dodatkowa struktura, będąca w gruncie rzeczy rejestrem przesuwającym. Składa się ona z dwóch terminali umiejscowionych na przeciwległych stronach ramki konstrukcji pętli (rys. 6). Terminal oznaczony strzałką skierowaną w górę jest wejściem rejestru, do którego realizuje się połączenie z wyjściem wybranego węzła poddiagramu pętli, który to dostarcza danej przekazywanej do następnej iteracji. Wyjściem rejestru jest terminal ze strzałką skierowaną w dół. Dostarcza on danej z poprzedniej iteracji lub wartość początkową dla pierwszego wykonania pętli.
Rys. 5. Diagram z tunelami wyjściowymi z autoindeksacją i bez niej
|

Rys. 6. Diagram wykorzystujący rejestr przesuwny
|
Rejestr może być zainicjowany daną z węzła lub terminala znajdującego się na zewnątrz pętli, pod warunkiem dołączenia go do terminala ze strzałką skierowaną w dół. Jeśli rejestr nie jest jawnie inicjalizowany, przyjmuje domyślne wartości danego typu – czyli zazwyczaj wartość numeryczną 0. Drugą możliwością jest wykorzystanie danych uzyskanych podczas wcześniejszego działania pętli, o ile tylko program wykonuje pętlę wielokrotnie. Rejestr przesuwny można stosować do dowolnego typu danych, ale raz utworzony nie może mieć przypisywanych danych różnego formatu. Tworzenie rejestru przesuwnego dokonuje się poprzez wybór z menu konstrukcji pętli opcji Add Shift Register. Aby utworzyć wieloelementowy rejestr należy wybrać z menu terminala pozycję Add Element. Każde dodanie elementu tworzy dodatkowy terminal ze strzałką skierowaną w dół. Terminale te są sklejone ze sobą. Utworzenie wieloelementowego rejestru pozwala korzystać z kilku danych pochodzących z kolejnych poprzedzających iteracji. Pętla może korzystać z wielu rejestrów przesuwnych.
Tworzenie formuł obliczeniowych
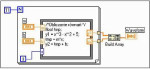
Ostatnim typem struktur określających operacje wykonywane na przetwarzanych danych są formuły obliczeniowe (rys. 7). Węzły formuł pozwalają na realizację operacji matematycznych zapisanych w formie tekstowej. Węzły te są przydatne w realizacji operacji, które korzystają z wielu zmiennych oraz produkują jeden lub więcej rodzajów danych wejściowych. Sposób zapisu bloku programu węzła Formula jest podobny do zapisu bloku instrukcji programu w języku C. W związku z tym, blok może zawierać deklaracje zmiennych, wyrażenia matematyczne oraz instrukcje sterujące if…then…else, switch....case, pętle for, while, do…while i inne. Dostępne formaty zmiennych to float i int. Wyrażenia matematyczne obowiązują takie same zasady i operatory jak w języku C. Wyjątkiem jest dodatkowy operator podnoszenia do potęgi, oznaczany jako x**y. Możliwe jest także stosowanie komentarzy umieszczanych pomiędzy znakami /* i */. Tworzenie konstrukcji formuły wspomagane jest przez odpowiednie menu, zawierające pozycje służące do kreowania wejść i wyjść węzła (odpowiednio Add Input oraz Add Output), które to stanowią zmienne formuły. Po wykreowaniu należy w polu utworzonego wejścia lub wyjścia wpisać jego nazwę. Nazwy muszą być unikalne w ramach danej konstrukcji, ale nazwa wyjścia może być taka sama jak jednego z wejść.
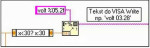
Drugim, węzłem podobnym do Formula jest struktura Expression. Służy on wyłącznie do obliczenia pojedynczego wyrażenia korzystającego z jednej zmiennej wejściowej. Węzeł taki posiada predefiniowane wejście i wyjście typu float. Nazwa zmiennej użyta w wyrażeniu jest automatycznie kojarzona z wejściem węzła, a wyjściu przypisywany jest wynik wyrażenia.
Rys. 7. Diagram Formula
|
Rys. 8. Diagram Expression
|
Zmienne programów VI
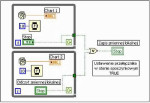
Jak to zostało wcześniej opisane, obiekty nastawcze pulpitu dostarczają dane do diagramu za pośrednictwem końcówek wejściowych, a obiekty wskaźnikowe pulpitu uzyskują dane z diagramu z końcówek wyjściowych. Z każdym obiektem pulpitu jest związana jedna końcówka wyjściowa lub wejściowa diagramu. Aplikacja może potrzebować dostępu do tych danych w różnych miejscach, a jednocześnie nie zawsze można to uzyskać za pomocą przewodów przepływu danych. Problem ten jest rozwiązywany poprzez zastosowanie zmiennych lokalnych i globalnych. Pierwsze z nich zapewniają dostęp do danych obiektu pulpitu w różnych miejscach pojedynczego programu VI, natomiast zmienne globalne mogą udostępniać i przenosić dane pomiędzy różnymi, jednocześnie realizowanymi programami. Jednakże stosowanie zmiennych w programach VI nie jest zalecane ponieważ przesłaniają one przepływ danych, a tym samym utrudniają analizę kodu i usuwanie ewentualnych błędów. Mogą być też przyczyną wielu dodatkowych problemów, takich jak niejednoznaczne zachowanie programu. Istnieją jednak sytuacje, gdy zastosowanie zmiennych jest w pełni uzasadnione. Przykładowo, aplikacja może stosować dwie równolegle działające pętle while, z czego w pierwszej z nich generowane są dane, z których na bieżąco korzystają diagramy pętli drugiej, wykonywanej równolegle z pierwszą. Nie ma innej metody udostępnienia danych z wnętrza działającej pętli niż przekazanie ich za pomocą zmiennej. Ponadto, zmienne lokalne pozwalają zapisywać dane obiektu panelu niezależnie czy są one obiektem sterującym czy wskaźnikowym. Operacje te funkcjonują tak samo jak przeniesienie danych do lub z końcówki obiektu w diagramie, z tym, że zapis zmiennej jest dostępny również w stosunku do obiektów sterujących pulpitu, które formalnie są źródłami danych. Dzięki temu, zmienne lokalne można wykorzystać nie tylko do uzyskania aktualnego stanu określonego obiektu sterującego, ale także do modyfikacji jego ustawienia, wyręczając tym samym operatora z obowiązku reagowania na niektóre z pojawiających się sytuacji. Bez zmiennych także byłoby to możliwe, ale użytkownik nie mógłby ingerować w ustawiane automatycznie parametry programu. Tworzenie zmiennej lokalnej w diagramie wymaga wykreowania jej oraz powiązania z określonym obiektem pulpitu, a także przeznaczenia jej do odczytu lub zapisu. Aby to uczynić, należy skorzystać z ikony znajdującej się w palecie struktur. Po jej przeciągnięciu do edytora diagramu pojawi się symbol zmiennej ze znakiem zapytania, wskazującym na potrzebę jej powiązania z obiektem pulpitu. Ustalenie powiązania i przeznaczenia zmiennej dokonuje się poprzez wykorzystanie menu kontekstowego – Select Item oraz Change to Read/Write. Proste zastosowanie zmiennej lokalnej zilustrowane zostało na rysunku 9. przedstawiającym przykład diagramu wykorzystującego równolegle działające pętle while, które przerywane są za pomocą przycisku STOP. Końcówka wejściowa obiektu STOP znajduje się wewnątrz jednej z pętli. Z powodu założenia równoległości działania obu pętli, nie można zastosować połączenia przepływu danych z tej końcówki do terminala kontynuacji drugiej pętli. Można jednak utworzyć zmienną lokalną związaną z obiektem STOP i wykorzystać ją w drugiej z pętli. Po zakończeniu działania obu pętli, przełącznik jest ustawiany w stanie spoczynkowym, a wykorzystanie zapisu do zmiennej powoduje, że przełącznik zachowuje się tak jak przycisk.
Rys. 9. Wykorzystanie mechanizmu zmiennych lokalnych
|
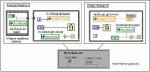
Rys. 10. Wykorzystanie mechanizmu zmiennych globalnych
|
Nieco inaczej niż zostało to wyżej opisane wygląda mechanizm tworzenia zmiennych globalnych. Są one wbudowanymi obiektami LabVIEW, których kreowanie powoduje automatyczne wytworzenie specjalnego globalnego interfejsu wirtualnego, który ma tylko panel – bez diagramu. Wprowadzenie obiektów nastawczych i wskaźników do tego panelu określa typy danych i składniki takiego obiektu globalnego, a zatem zmienna globalna może mieć postać złożoną, zapewniającą przekazywanie bardzo różnych danych. Jej panel można traktować jako kontener, z którego korzystają różne podprogramy VI. Aby utworzyć zmienną globalną, należy wybrać ikonę GLOB z palety struktur i przeciągnąć ją do diagramu aplikacji. Spowoduje to utworzenie symbolu graficznego zmiennej w postaci prostokąta ze znakiem zapytania sygnalizującym brak jej pełnego zdefiniowania. Drugim powstałym elementem będzie niewidoczny interfejs wirtualny z pustym pulpitem. W celu pełnej konfiguracji zmiennej należy otworzyć pulpit za pomocą opcji Open Front Panel i umieścić na nim odpowiednie obiekty odpowiadające typom danych, które składają się na tworzoną zmienną globalną. Tak utworzony program VI należy zapisać pod unikalną nazwą. Zdefiniowaną zmienną globalną wprowadza się do aplikacji przez otwarcie określonego globalnego programu VI i przeciągnięcie jego ikony do jej diagramu. W miejscu docelowym trzeba jeszcze określić czy zmienna ma być wykorzystywana do odczytu czy do zapisu oraz wybrać odpowiedni składnik, gdy zmienna jest złożona z wielu elementów.
Na rysunku 10. został przedstawiony prosty przykład zastosowania zmiennej globalnej do przekazywania danych pomiędzy dwoma równolegle wykonywanymi programami VI. Pierwszy generuje cyklicznie wartości, a drugi prezentuje je na swoim pulpicie. Uaktualnianie następuje co dwie sekundy na podstawie zawartości składnika Number to Pass zmiennej globalnej. Składnik Stop Button tej samej zmiennej pozwala przerwać działanie programu Generate Number wraz z zatrzymaniem programu Display Number.
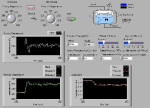
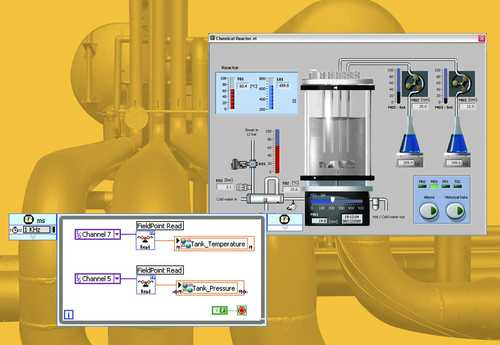
Rys. 11. Okno przykładowego wirtualnego interfejsu wykonanego w programie LabVIEW
|

Fot. 12. Zestaw urządzeń z rodziny Elite firmy Lion Precision, zaprojektowany z przeznaczeniem do współpracy z LabVIEW
|
Artykuł pod redakcją Marcina Karbowniczka. Tekst powstał na bazie artykułu publikowanego na stronie Polskiego Centrum LabVIEW (www.LabVIEW.pl) i opracowanego przez dr inż. Bogdana Kasprzaka. Redakcja dziękuje autorowi tekstu za jego udostępnienie i poleca korzystanie z serwisu www.LabVIEW.pl.









