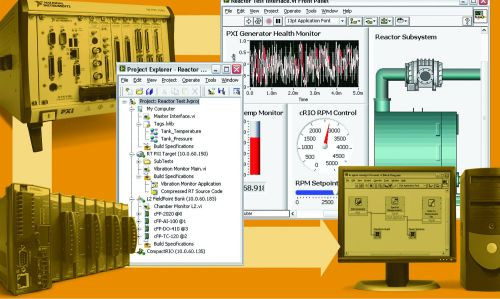
Skrót VI w nazwie programu LabVIEW VI pochodzi od angielskich słów Virtual Interface i oznacza możliwość tworzenia wirtualnych interfejsów urządzeń pomiarowych. Przyrządy te połączone są z komputerem na którym uruchomiony jest program LabVIEW i komunikują się między sobą poprzez wirtualne środowisko pomiarowe. Ponieważ konkretna aplikacja może wymagać wykorzystania wielu urządzeń pomiarowych i sterujących jednocześnie, konieczne było stworzenie interfejsu za pomocą którego użytkownik mógłby kontrolować przeprowadzane pomiary. Interfejs ten, którym jest LabVIEW, pozwala nie tylko na rozpoczęcie i zakończenie cyklu pomiarowego, ale również na zaawansowane przetwarzanie i wizualizację w czasie rzeczywistym wyników pomiarów, jak też definiowanie parametrów pracy wykorzystywanych urządzeń.
Podstawowe składniki programu LabVIEW
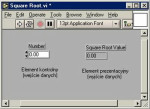
Opisane powyżej podejście ma odzwierciedlenie w podziale programu LabVIEW tak, aby maksymalnie ułatwić pracę użytkownika i zarazem oddzielić od siebie części graficzną, strukturalną i obiektową. W związku z tym na LabVIEW składają się trzy moduły – moduł interfejsu graficznego, nazywany też pulpitem, moduł diagramu odpowiadającego za strukturę połączeń pomiędzy poszczególnymi urządzeniami, jak i za strukturę programu badań oraz moduł pozwalający na łączenie kilku wirtualnych urządzeń LabVIEW w jedno.
Pierwsza z wymienionych części ma wygląd przedniego panelu urządzenia pomiarowego. Poszczególne znajdujące się w nim obiekty graficzne mają odzwierciedlenie w wejściach oraz wyjściach sterownika i reprezentują dane otrzymywane, a także wysyłane do sterowanych z programu urządzeń. Końcówki wyjściowe sterownika to wszelkiego rodzaju pokrętła, przyciski i przełączniki symulujące elementy nastawcze wykorzystywanych urządzeń. Tymczasem sygnały wejściowe reprezentowane są przez wyświetlacze numeryczne, alfanumeryczne, diody LED, wyświetlacze graficzne (wykresy), tabele itp.
Aby wymienione elementy panelu operatorskiego mogły działać poprawnie, konieczne jest przypisanie ich do odpowiednich wejść i wyjść urządzeń fizycznie podłączonych do magistrali sterownika. W tym celu wykorzystywany jest graficzny diagram, opisany za pomocą języka G. W skład języka wchodzą takie elementy jak końcówki (terminals), węzły (nodes), przewody (wires) oraz konstrukcje sterujące (structures).
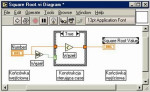
Pierwsze z nich reprezentują porty wejściowe i wyjściowe przesyłające informacje pomiędzy pulpitem i diagramem. Dane wprowadzone za pomocą elementów kontrolnych pulpitu są przekazywane do diagramu przez końcówki kontrolne. Z kolei dane przekazywane w drugą stronę są wyświetlane są za pomocą odpowiednich elementów prezentacyjnych na pulpicie. Poszczególne końcówki generowane są automatycznie w diagramie w momencie wstawienia elementu kontrolnego lub prezentacyjnego na pulpicie. Każda z końcówek reprezentuje port określonego elementu pulpitu oraz ma przypisany konkretny typ przesyłanych przez nią danych. Przykładem mogą być np. liczby rzeczywiste zmiennoprzecinkowe typu double, które oznaczane w LabVIEW skrótem DBL.
Drugim typem występujących w diagramie obiektów są węzły. Każdy z węzłów reprezentuje funkcję lub wyrażenie matematyczne, ewentualnie procedurę zapisaną w języku tekstowym. Służą one do wykonywania operacji przetwarzania danych, tak by dane one zostać przesłane w odpowiedniej postaci do sterownika lub urządzeń pomiarowych.
Trzecim z wymienionych wcześniej typów obiektów są elementy reprezentujące połączenia pomiędzy składowymi diagramu. Pozwalają one na przesyłanie danych pomiędzy zestawionymi blokami, przy czym każde połączenie może być rozgałęzione do wielu bloków odbierających dane, lecz mieć tylko jedno źródło danych. Połączenia są rysowane różnymi kolorami, stylami i grubością linii, w zależności od typu przesyłanych nimi danych. Połączenia wykryte przez kompilator jako niepoprawne – np. z powodu podłączenia wejścia i wyjścia o dwóch niekompatybilnych ze sobą formatach danych – wyróżniane są czarną przerywaną linią.
Ostatnim z elementów języka graficznego mogących wystąpić w widoku struktury projektu są konstrukcje sterujące. Zapewniają one specyficzny sposób wykonania programu, dzięki czemu pozwalają na realizację przetwarzania bloków kodu w pętlach, wprowadzanie instrukcji warunkowych lub też ustalenie sekwencji wykonywania poszczególnych bloków kodu.
Stworzony diagram, który obrazuje strukturę programu, może być wykorzystany wielokrotnie, o ile wygenerowane zostanie tzw. złącze. Definiuje ono wszystkie wejścia i wyjścia podprogramu odpowiadające elementom kontrolnym i prezentacyjnym panelu. Tym samym umożliwia wykonanie odpowiednich połączeń w diagramie zawierającym dany podukład, który reprezentowany jest w diagramie jako ikona tworzona podczas generowania złącza.
Jak zadziała program LabVIEW?
Stworzony diagram powinien odwzorowywać poszczególne elementy procedury pomiarowej. Rozpoczyna się on od końcówek wejściowych elementów kontrolnych pulpitu (np. Input 1 i 2) i węzłów (np. Const DBL) będących źródłem stałych wartości określonego typu, a kończy na wyjściach. Linie wyznaczające drogi przepływu danych mogą się zbiegać w wielowejściowych węzłach, takich jak węzły dodawania lub odejmowania. Każdy węzeł diagramu wykonuje swoje operacje tylko raz. Kolejność wykonania operacji jest określona przepływem danych (dataflow). Każdy z węzłów diagramu rozpoczyna działanie po otrzymaniu wszystkich potrzebnych danych wejściowych. Następnie, po wykonaniu charakterystycznych dla niego operacji, dostarcza wyniki na swoje wyjścia - dane te przesyłane są połączeniami do kolejnych węzłów. Wykonywanie programu można rozpatrywać jako kolejne fazy przetwarzania danych przez węzeł i ich przekazywania do węzłów odbierających. Warto zaznaczyć, że podczas wykonywania programu dane wyjściowe z węzłów pojawiają się i dostarczane są do węzłów odbierających jednocześnie.
W przypadku bardziej skomplikowanych diagramów, które zawierają wiele równoległych gałęzi, które obejmują szeregowo połączone węzły, ustalenie kolejności wykonania programu może być zadaniem trudnym. Ponadto nie można ustalić kolejności wykonywania operacji przez węzły, które uzyskały stan gotowości, gdyż będą one pracowały pseudo-jednocześnie. Sprawa staje się jeszcze trudniejsza gdy w skład diagramu wchodzą ikony reprezentujące inne poddiagramy. Środowisko samo decyduje o kolejności działań stosując technikę arbitralnego przeplotu. W ten sposób węzły lub grupy węzłów różnych gałęzi są wykonywane przemiennie, co skutkuje ich równoległym wykonywaniu w czasie. Warto nadmienić, że kolejność wykonania węzłów diagramu może różnić się w kolejnych uruchomieniach programu.
Następną kwestią konieczną do rozwiązania, jest sprawa węzłów, które mogą działać niezależnie, ale jednocześnie wymagane jest, aby pewnego rodzaju operacje były wykonywane w określonej kolejności. Przykładem takiej sytuacji są operacje odczytu i zapisu do pliku. O ile plik jest gotowy do odczytu i do zapisu przez cały czas za wyjątkiem momentów, gdy jest realizowana któraś z wymienionych operacji, często może zdarzyć się, że odczyt powinien być poprzedzony zapisem aktualizującym zawarte w pliku dane. Podobnie jest z wieloma urządzeniami pomiarowymi, które dokonują pomiaru dopiero na rozkaz ze sterownika, a do tego czasu w razie odpytania zwracają poprzednio zmierzoną wartość. Z tych powodów węzły funkcji I/O mają wejścia deskryptorów i błędów oraz takie same wyjścia. Po wykonaniu operacji tego typu węzeł dostarcza danych zarówno na wyjście deskryptora jak i wyjście błędu. Dzięki połączeniu tych wyjść z odpowiadającymi wejściami kolejnego, podobnego węzła zapewniona jest żądana kolejność wykonywania operacji, która wynika z przepływu danych. Oczywiście mogą
zaistnieć sytuacje w których wymaganej kolejności nie daje się uzyskać bezpośrednio z przepływu danych. Trzeba wówczas zastosować odpowiednie konstrukcje sterujące, które pozwalają na wymuszanie porządku wykonywania bloków.
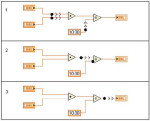
Rys. 5. Kolejne etapy wykonania prostego diagramu VI
|
Rys. 6. Przykład kolejności wykonania węzłów diagramu VI z równoległymi gałęziami (numery przy węzłach podają kolejność wykonania)
|
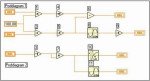
Rys. 7. Przykład kolejności wykonania węzłów dwóch niezależnych poddiagramów programu VI (numery przy węzłach podają kolejność wykonania)
|
Sekwencjonowanie operacji - struktury programów LabVIEW
W języku G, czyli w tym w którym tworzone są struktury programów LabVIEW VI, konstrukcja sekwencyjna przedstawiana jest jako ramka filmu i składa się z jednej lub kilku klatek, także często nazywanych ramkami. Pozwala ona na kolejne wykonywanie kodu programu zgodnie z numeracją klatek. Konstrukcje sekwencyjne stosuje się do wymuszenia określonej kolejności wykonywania fragmentów kodu, gdy nie daje się tego uzyskać stosując przepływem danych. Sekwencję można rozbudować do dowolnej liczby ramek.
Podczas prowadzenia połączeń pomiędzy węzłami znajdującymi się wewnątrz ramek a tymi, które umieszczone są w innych ramkach lub zupełnie poza nimi, automatycznie tworzone są tzw. tunele wejść i wyjść. O ile dane wejściowe konstrukcji są dostępne dla wszystkich jej ramek, o tyle wyjścia danych mogą mieć tylko jedno źródło informacji. Innymi słowy każde z wyjść struktury jest związane z jedną z klatek, ale tunele wyjściowe widoczne są we wszystkich klatkach. Dane opuszczają strukturę dopiero w momencie, gdy zakończone zostanie wykonywanie kodu zawartego w ostatniej ramce. Oznacza to, że dane z wcześniejszych klatek struktury będą dopiero dostępne gdy kod z całej struktury zostanie wykonany.
Kwestia przekazywania danych pomiędzy kolejnymi klatkami struktury realizowana jest za pomocą terminala zwanego lokalną sekwencją. Aby go wykorzystać należy zastosować funkcję Add Sequence Local, klikając odpowiednio w menu kontekstowym (uaktywniany prawym klawiszem myszy). Lokalna sekwencja zaznaczona jest symbolem końcówki przenoszenia danych we wszystkich ramkach struktury. W ramce będącej źródłem danych dla lokalnej sekwencji punkt przekazywania danych zaznaczony jest zewnętrznym zwrotem strzałki, a w ramce odbiorczej strzałką zwróconą do jej wnętrza. Ramki poprzedzające tę, która jest źródłem danych, nie mogą oczywiście korzystać z informacji przenoszonych sekwencją lokalną - w ich przypadku punkt przenoszenia jest zamalowany i nie zawiera symbolu strzałki.
W przykładzie przedstawionym na rysunku 10. pokazano czteroklatkową konstrukcję z lokalną sekwencją przekazywania danej obliczonej przez diagram klatki numer 1. Kolejne klatki otrzymują dane za pośrednictwem terminala wejściowego lokalnej sekwencji, ale nie muszą jej wykorzystywać. Ramka o numerze 0 wykonuje się przed ramką numer 1, więc nie może korzystać z terminala sekwencji lokalnej.
Konstrukcja sekwencyjna pozwala szeregować różne operacje, co, jak zostało wcześniej zaznaczone, nie zawsze jest możliwe do uzyskania jedynie za pomocą mechanizmu dataflow. Przykład z rysunku 11. pokazuje zastosowanie sekwencji do odmierzania czasu wykonania pewnego kodu, który umieszczony został w ramce o numerze 0. Do tunelu wejściowego podawany jest czas inicjalizacji programu, który następnie wykorzystywany jest w drugiej ramce struktury. W niej następuje pobranie nowej wartości licznika, która odczytywana jest w momencie zakończenia pracy diagramu z ramki 0. i rozpoczęciu przetwarzania ramki 1. W niej także pobierana jest wartość początkowa licznika i dokonywana operacja odejmowania od siebie obydwu wartości zegarowych w celu ustalenia czasu wykonania zadania z ramki 0. Niemniej dokładność tego pomiaru nie jest zawsze identyczna i zależy od większej liczby czynników, których opis wykracza poza ramy niniejszego artykułu.
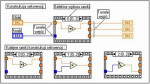
Rys. 9. Przykład konstrukcji sekwencyjnej oraz kolejne jej ramki (klatki)
|
Rys. 10. Ramki konstrukcji sekwencyjnej z lokalną sekwencją przekazywania danych
|
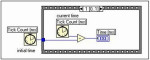
Rys. 11. Przykład wykorzystania konstrukcji sekwencyjnej do odmierzenia czasu wykonania kodu umieszczonego w ramce 0
|
Wprowadzanie instrukcji warunkowych w LabVIEW
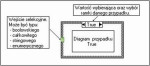
Wszyscy, którzy mieli kiedykolwiek okazję korzystać z dowolnego języka programowania, prawdopodobnie wiedzą, że do napisania większości programów konieczne jest korzystanie z instrukcji warunkowych. Bez nich program byłby tylko zbiorem kolejno wykonywanych poleceń, które w żaden sposób nie wyręczyłyby użytkownika z obowiązku kontroli pracy systemu i podejmowania decyzji co do jego dalszego działania. Nie inaczej jest z wykorzystanym w LabVIEW VI językiem G, który także zawiera możliwość wprowadzenia konstrukcji warunkowych. Stworzona w tym celu instrukcja case odpowiada funkcjonalnie poleceniom if...then...else lub switch z języka C. Konstrukcja składa się z dwóch ramek, z których każda zawiera blok programowy realizujący określone operacje oraz deklarację wybieranych wartości. Działanie funkcji polega na wykonaniu kodu zawartego w jednej z ramek, której wybór realizowany jest na podstawie danej dostarczonej do wejścia selekcyjnego konstrukcji case.
Wejście selektora konstrukcji case może przyjmować dane w różnym formacie. Zależnie od tego dostępne będą dwie klatki reprezentujące rozgałęzienia programu dla poszczególnych wartości w przypadku selektora typu boolowskiego (TRUE / FALSE) albo, w przypadku selektora o formacie liczb całkowitych, formacie tekstowym lub wyliczeniowym, maksymalnie 231-1 klatek.
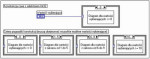
W drugim przypadku do każdej z możliwych wartości selektora musi być również przypisana jedna z ramek konstrukcji case. Określenie stałych wybierających ramkę realizuje się poprzez wpisanie ich listy w okienku wartości wybierających. W przypadku wyboru danych całkowitych pole wartości wybieranej daną ramkę może mieć postać pojedynczej liczby, listy, zakresu lub wartości domyślnej oznaczanej jako Default. W przypadku zastosowania listy poszczególne liczby oddzielane są przecinkami i spacjami, podczas gdy oznaczenie zakresu dokonywane jest przez wstawienie znaku dwóch sąsiadujących ze sobą kropek pomiędzy graniczne liczby przedziału. Przykładem tych opcji będą odpowiednio: „1, 3, 13, 19” i „5..23”.
Ponieważ konieczne jest, aby konstrukcja wyboru obsługiwała wszystkie możliwe przypadki, zaleca się wprowadzenie jednej z ramek z wcześniej wspomnianym oznaczeniem Default. Dzięki temu wszystkie wartości selektora, które nie zostały przypisane do innych ramek konstrukcji spowodują wykonanie diagramu umieszczonego w ramce Default. Jest to także dobra metoda na sygnalizację błędów, które mogą objawiać się wystąpieniem na selektorze wartości, która nie została przewidziana przez programistę. Pozwoli to na zatrzymanie pracy lub przejście systemu w bezpieczny stan, gdy tylko wystąpi błąd. Naturalnie, ramka Default nie będzie miała większego znaczenia w przypadku stosowania selektora typu boolowskiego.
Ponieważ każda ramka struktury warunkowej definiuje wyjścia danych, które widoczne są na zewnątrz, po wykonaniu zadań struktura musi dostarczyć dane na wszystkich jej wyjściach – również na tych, które dotyczą ramek aktualnie nierealizowanych. Z tego powodu diagram każdej ramki musi dostarczyć dane na wszystkie wyjścia struktury warunkowej – także te utworzone na potrzeby innych klatek i formalnie nieistotne dla algorytmu realizowanego w danym przypadku. Wartość danej dostarczanej na takie wyjście zależy od ogólnej koncepcji rozwiązania danego programu. Często wprowadza się także stałe określonego typu. Oczywiście jeśli wyjścia ramek struktury korzystają z tego samego formatu danych, ich diagramy mogą być podłączone do tego samego tunelu wyjściowego. Oznacza to, że nie trzeba tworzyć bardzo wielu, osobnych wyjść dla każdej klatki.
|
Firma National Instruments udostępnia darmową wersję ewaluacyjną programu LabVIEW w sieci Internet. Aby pobrać pakiet należy wejść na stronę www.ni.com/labview/ i wybrać z lewego menu How to Buy oraz LabVIEW Development System. Następnie, po wybraniu zakładki Resources i kliknięciu linku Evaluation Software na ekranie ukaże się lista dostępnego oprogramowania. Po wybraniu pozycji LabVIEW 8.20 Evaluation Software Download należy wybrać Online Request Form i postępować zgodnie ze wskazówkami pojawiającymi się na ekranie. Objętość pliku do pobrania wynosi 542MB. |
O ile opisane powyżej metody tworzenia programów w LabVIEW mogą być wystarczające do przeprowadzania pojedynczych pomiarów, należy uzupełnić je o konstrukcje pętli, co pozwoli na cykliczne powtarzanie badań. Ponadto, w bardziej skomplikowanych układach pomiarowych, konieczne jest skorzystanie z dodatkowych zmiennych. Na te oraz inne tematy, dotyczące np. obliczania wartości wyrażeń arytmetycznych i przetwarzania danych w LabVIEW, można przeczytać w drugiej części artykułu, która ukaże się w styczniowym numerze APA.
Post scriptum: Co nowego w LabVIEW 8.20?
Opisywane w artykule techniki programowania stanowią jedynie podstawy korzystania z LabVIEW, które nie zmieniły się już od wczesnych wersji tego programu. Tymczasem firma National Instruments oferuje od niedawna jubileuszową wersję programu oznaczoną numerem 8.20, która wydana została z okazji 20-lecia obecności LabVIEW na rynku. Spośród zmian w stosunku do wersji poprzedniej (o numerze 8.0) warto wspomnieć o nowych elementach wspomagających programowanie obiektowe, rozszerzonych możliwościach w zakresie obliczeń matematycznych (kompatybilność z MathScript) oraz nowych, przyspieszonych funkcjach obsługi plików. Ponadto wprowadzono możliwość wykorzystania bibliotek DLL oraz Microsoft .NET Web Services. Usprawniony został także mechanizm sterowania za pomocą zdalnego interfejsu graficznego poprzez wielu użytkowników jednocześnie, dodano również szereg kreatorów ułatwiających tworzenie aplikacji. W nowej wersji LabVIEW rozbudowany został zestaw dostępnych funkcji bibliotecznych służących przetwarzaniu sygnałów. W celu zabezpieczenia tworzonych aplikacji wprowadzono system automatycznego tworzenia kopii zapasowych i odzyskiwania utraconych programów. Ponadto firma National Instruments wprowadziła LabVIEW Touch Panel Module, co pozwala na tworzenie przemysłowych interfejsów HMI.
Artykuł pod redakcją Marcina Karbowniczka. Tekst powstał na bazie artykułu zawartego na stronie Polskiego Centrum LabVIEW (www.labview.pl) i opracowanego przez dr inż. Bogdana Kasprzaka. Redakcja dziękuje autorowi tekstu za jego udostępnienie i poleca korzystanie z serwisu www.labview.pl.
Druga część artykułu Szkoła LabVIEW








