
Systemy wizyjne to niezbędny komponent linii technologicznych. Dostarczają maszynom i robotom przemysłowym dane o zmianach warunków na stanowisku w czasie rzeczywistym. Dzięki temu te pracują elastyczniej i wykonują zadania bardziej zaawansowane niż tylko przemieszczanie się po zaprogramowanej wcześniej ścieżce, jak: nawigacja, inspekcja, pomiary, identyfikacja.
Przykład maszyn wykorzystujących informacje z systemu wizyjnego, aby zorientować się w otoczeniu, to autonomiczne roboty mobilne popularne w logistyce. Kamery naprowadzają również roboty na stanowiskach pick and place. W zadaniu inspekcji na stanowiskach kontroli jakości i sortowania systemy wizyjne rozpoznają obiekty wybrakowane albo te, które różnią się od innych. Na liniach montażowych dokonują pomiarów. Identyfikacja z kolei obejmuje skanowanie kodów kreskowych, odczyt oznaczeń i rozpoznawanie cech.
We wszystkich tych zadaniach tradycyjne systemy wizyjne rozróżniają szczegóły niewidoczne gołym okiem, działając z nieosiągalną przez ludzi dokładnością, powtarzalnością i szybkością. Dzięki temu przewiduje się, że nawet upowszechnienie się sztucznej inteligencji nie zagrozi ich ugruntowanej pozycji rynkowej. Mają jednak pewne ograniczenia.
Systemy wizyjne oparte na regułach
Interpretując dane wejściowe tradycyjne systemy wizyjne opierają się na zestawie reguł, pod kątem których zostały zaprogramowane. Zaletą tego podejścia jest szybkość programowania. Przeważnie w komplecie ze sprzętem dostępne jest oprogramowanie z biblioteką funkcji wykrywania w obrazie określonych cech. Przykładami są: lokalizacja obiektu, detekcja krawędzi, wykrywanie wad, pomiar różnych cech, odczytywanie kodów kreskowych, rozróżnianie kolorów oraz rozpoznawanie znaków. Algorytmy te wykorzystują różne techniki przetwarzania obrazów, na przykład analizę histogramu, dla którego wyznaczane są różne statystyki, na przykład: liczba pikseli, ich średnia, najmniejsza i maksymalna wartość, odchylenie standardowe, wariancja. Na tej podstawie określane są jasność i kontrast w obrazie, co pozwala na wykrycie w nim wzorców. Program, który realizuje system wizyjny, jest kombinacją funkcji dobranych pod kątem potrzeb danego zastosowania.
Niestety wiele czynników ma wpływ na wyniki. By go zminimalizować, opracowuje się filtry, które na przykład: korygują nierównomierne oświetlenie i zacienienie obrazu, usuwają tło, wzmacniają wybrane kolory, obracają i prostują obraz, wzmacniają kontrast, usuwają odblaski i wyostrzają krawędzie. Ich skuteczność w detekcji nietypowych zniekształceń (zmienione proporcje obrazu zarejestrowanego pod kątem, zakryte oznaczenia, pomarszczone etykiety, nietypowe tekstury) i dostrzegania subtelnych różnic nie jest jednak zadowalająca. Pod tym względem systemy wizyjne nie dorównują ludziom. Choć bowiem tempo, w jakim przetwarzamy informacje, jest wolniejsze uczymy się na przykładach, potrafimy wyciągać wnioski, ważyć dane i decydować, co jest ważniejsze w danym przypadku, dostrzegać drobne różnice, interpretować nietypowe dane.
Tymczasem systemy wizyjne oparte na regułach wymagają zakodowania każdej możliwości w formie warunku jeżeli... to... Uwzględnienie wszystkich możliwych kombinacji wszystkich cech, odchyłek od nich, zależności między nimi i szczególnych przypadków sprawia, że zestaw reguł rozrasta się. Optymalnym rozwiązaniem byłoby więc połączenie możliwości przetwarzania maszyn ze zdolnościami uczenia się i wnioskowania ludzi. Umożliwia to sztuczne inteligencja.
Czym jest głębokie uczenie?
Gałęzią sztucznej inteligencji rozwijaną obecnie najdynamiczniej jest uczenie maszynowe (machine learning). Jego celem jest zdobywanie umiejętności lub wiedzy z doświadczenia, tzn. ich synteza na podstawie danych historycznych. W praktyce znaczy to, że w przeciwieństwie do algorytmów, które opierają się na zestawach reguł jeśli... to, w uczeniu maszynowym algorytm uczy się klasyfikowania danych wejściowych na podstawie ich próbek. Wyróżnić można trzy kategorie algorytmów uczenia maszynowego: nadzorowane, nienadzorowane, przez wzmocnienie. Najbardziej perspektywicznym podzbiorem, również w kontekście systemów wizyjnych, jest nadzorowane głębokie uczenie (deep learning).
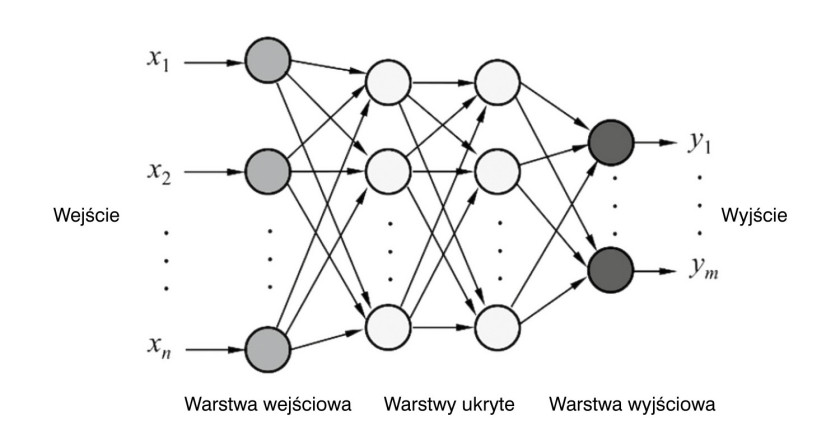
Inspiracją dla tej techniki jest ludzki mózg i to, jak są w nim zorganizowane synaptyczne połączenia między neuronami. Dzięki temu algorytmy głębokiego uczenia poddają dane analizie w sposób podobny do tego, w jaki ludzie wyciągają wnioski. Umożliwia to sztuczna sieć neuronowa, czyli warstwowa struktura algorytmów, która uczy się i podejmuje decyzje samodzielnie. Jest ona zbudowana z warstw: wejściowej, wyjściowej oraz ukrytych wykorzystywanych w wewnętrznych obliczeniach. Im więcej jest tych ostatnich tym sieć jest głębsza.
Na przykład w zadaniu rozpoznawania znaków warstwa wejściowa wyodrębnia atrybuty znaku, który ma się uczyć rozróżniać, jak: punkty, krawędzie, kolory czy obiekty. Warstwy ukryte uczą się je wykrywać, jedna na przykład krawędzie, kolejne – konkretne kształty. Warstwa wyjściowa odpowiada za klasyfikację na podstawie tych cech. Po zasileniu danymi treningowymi algorytm głębokiego uczenia, ucząc się na własnych błędach, w końcu jest w stanie rozpoznawać różne znaki.
Sieci neuronowe w praktyce
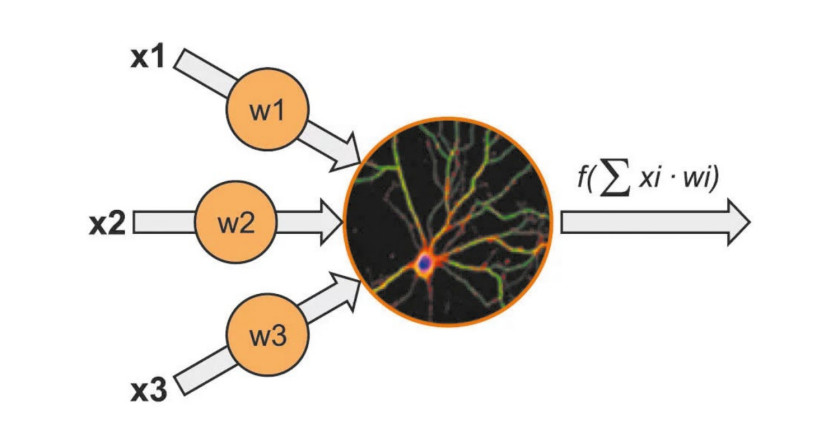
Najprostszy model sztucznej sieci neuronowej składa się z pojedynczego neuronu (perceptronu). Suma ważona jego wejść, które w neuronie biologicznym byłyby dendrytami, jest argumentem funkcji. Jej wynik jest natomiast odpowiednikiem aksonu neuronu biologicznego. Pojedyncze neurony można ułożyć jeden na drugim, tworząc warstwy, które następnie umieszcza się obok siebie, by sieć była głębsza. Połączeniom pomiędzy poszczególnymi neuronami też przypisuje się wagi. Przez ich wartość przemnaża się wyjście jednego neuronu, przekazywane jako wejście drugiego, z którym pierwszy jest połączony. W procesie uczenia się na danych treningowych te wagi są korygowane tak, żeby zmniejszyć liczbę błędów. Sieci neuronowe z głębokim uczeniem wyróżniają się tym, że doskonalą się w miarę przetwarzania nowych danych, szybciej, im większa jest dana struktura.
Kluczowe znaczenie dla skuteczności algorytmu głębokiego uczenia ma jakość danych testowych. W szkoleniu sztucznej sieci neuronowej pod kątem zastosowania w systemach wizyjnych ważne jest, by obrazy referencyjne były rejestrowane w podobnych warunkach (oświetlenie i ustawienia kamer) do tych w systemie docelowym. Zbiór obrazów powinien być reprezentatywny dla danej aplikacji, obejmując potencjalne zmiany w wyglądzie i prezentacji przedmiotu i jego otoczenia i wystarczająco liczny. Odpowiednia liczba obrazów testowych zależy od złożoności zadania oraz zmienności warunków (na przykład czy wykrywane mają być wyraźne, czy raczej subtelne różnice między obrazami podobnych obiektów, czy analizowane obrazy będą przedstawiały jeden obiekt na jednolitym tle).
Dane treningowe dzieli się na trzy grupy do: stworzenia modelu, kontroli procesu uczenia przez śledzenie różnicy między uzyskanymi a prawidłowymi wynikami klasyfikacji i końcowej oceny wydajności wytrenowanego modelu. Uczenie może mieć charakter od podstaw lub transferowy, jeśli korzysta się z wiedzy pozyskanej wcześniej w szkoleniu modelu do innego zastosowania. Gotowy model testuje się pod względem szybkości i dokładności.
Głębokie uczenie w systemach wizyjnych
Głębokie uczenie jest techniką skuteczną, ale by uzyskać poziom dokładności wymagany zwykle w przemyśle (minimum 99,7%), wymaga długiego trenowania sieci neuronowej na odpowiednio dobranych danych testowych. Ponadto generalnie jego domeną jest klasyfikowanie danych i w związku z tym nie we wszystkich zastosowaniach systemów wizyjnych jest równie skuteczne.

Najlepiej sprawdza się w rozpoznawaniu obiektów i ich cech, na przykład stwierdzaniu różnicv między nimi. Domeną głębokiego uczenia jest również wykrywanie różnego rodzaju defektów, także na obrazach z niejednolitym lub teksturowanym tłem. Dobre wyniki zapewnia ponadto w rozpoznawaniu znaków tekstowych i symboli, jak daty ważności i kody partii. Z drugiej strony w dopasowywaniu do wzorców lub pomiarach wymagających bardzo dużej precyzji głębokie uczenie nie sprawdza się aż tak dobrze jak tradycyjne algorytmy systemów wizyjnych. Poza zakresem jego zastosowania leży też dekodowanie kodów kreskowych i dwuwymiarowych symboli.
Głębokie uczenie powinno być zatem raczej uzupełnieniem klasycznego oprogramowania używanego w zautomatyzowanej wizualnej: identyfikacji, inspekcji, naprowadzaniu i pomiarach, a nie jego zamiennikiem. Projektując system wizyjny, warto rozważyć wybór oprogramowania, które obejmuje zarówno narzędzia konwencjonalne, jak i te oparte na głębokim uczeniu. Ma je w swojej ofercie coraz większa liczba dostawców.
Monika Jaworowska









