W prezentowanym artykule zostaną przedstawione podstawowe funkcje sterowników programowalnych PLC Simatic firmy Siemens, które umożliwiają przeprowadzenie testów diagnostycznych. Ich dobra znajomość pozwala na szybką reakcję, próbę poprawy działania aplikacji oraz skrócenie czasu przestoju, co powoduje zmniejszenie strat i poniesionych kosztów związanych z zaistniałymi błędami.
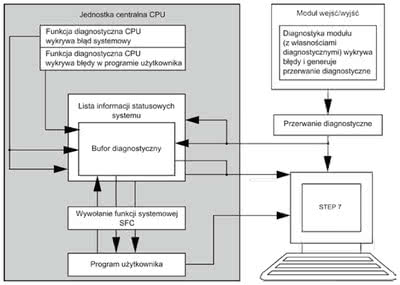
Rys. 1. Współpraca jednostki centralnej (CPU) sterownika, modułu wejść/ wyjść i programatora (np. stacja PC) podczas wystąpienia zdarzenia diagnostycznego |
Sterownik PLC stanowi jeden z elementów, którego praca powinna zostać dokładnie przeanalizowana zarówno podczas projektowania aplikacji, jak i w trakcie wystąpienia awarii maszyny lub błędów w procesie technologicznym. Jego diagnostyka polega na ocenie działania aplikacji zaprojektowanej na danym sterowniku, a funkcje diagnostyczne służą do rozwiązywania błędów powodujących jego nieprawidłowe działanie.
W sterownikach Simatic zaimplementowano wiele mechanizmów pozwalających na szybkie wykrywanie błędów. Dzięki temu proces diagnostyki staje się usystematyzowany zarówno na poziomie testów, jak i już działającej aplikacji. W artykule opisano podstawowe procedury diagnozowania błędów sterownika PLC S7- 300 z wykorzystaniem środowiska STEP 7.
Kategorie błędów
Błędy występujące w systemie sterowania możemy podzielić na dwie kategorie w zależności od miejsca ich powstania:
- Błędy systemowe - są identyfikowane przez system operacyjny sterownika PLC i sygnalizowane stanem diod na CPU. W momencie wystąpienia błędu CPU może przejść w tryb Stop i przerywa wykonywanie programu sterowania. Błędy systemowe mogą mieć źródło wewnętrzne lub zewnętrzne. Źródłem wewnętrznym błędów systemowych są stany nieprawidłowe, zlokalizowane w obrębie samej jednostki CPU - np. utrata komunikacji ze zdalną kasetą I/ O, wykonanie przez program użytkownika niedozwolonej operacji matematycznej, przekroczenie czasu cyklu CPU, zaadresowanie przez program nieistniejącego obszaru pamięci lub wywołanie nieistniejącej funkcji. Źródłem zewnętrznym są usterki zlokalizowane poza samą jednostką centralną np. w modułach I/O, poszczególnych kanałach modułów I/O lub np. w zasilaniu CPU i modułach I/O. Błędy systemowe są stosunkowo łatwe do zlokalizowania, ponieważ istnieje możliwość podłączenia komputera z oprogramowaniem narzędziowym do sterownika PLC.
- Błędy funkcjonalne - w tym przypadku CPU przetwarza program sterowania, jednak zaprogramowana przez użytkownika funkcja nie jest w całości przetwarzana lub jest przetwarzana błędnie. Występują dwa typy błędów funkcjonalnych:
- Błędy procesowe - są identyfikowane jako nieprawidłowe funkcjonowanie odpowiednich elementów systemu sterowania m.in. okablowania czujnika/elementu wykonawczego lub uszkodzenie czujnika/elementu wykonawczego. Są to błędy generowane przez program użytkownika w wyniku analizy przez algorytm sterujący informacji z czujników, stanów wewnętrznych i sekwencji zdarzeń programu. W poprawnie skonstruowanym systemie sterowania błędy tej kategorii powinny być dokładnie identyfikowane i lokalizowane. Informacja o zaistnieniu, czasie i miejscu zdarzenia powinna być wyświetlana na panelach operatorskich, systemach wizualizacji lub tablicach synoptycznych.
- Błędy logiczne programu - są to błędy programowe, które nie zostały zidentyfikowane podczas pisania oraz uruchomienia programu i nieobsłużone przez mechanizm alarmów procesowych użytkownika. Przykładowo może to być dwukrotne wysterowanie wyjścia w programie, złe adresowanie wejść/wyjść, itp.

TABELA 1. Symbole diagnostyczne opisujące jednostkę centralną lub moduł funkcyjny |
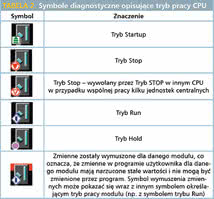
TABELA 2. Symbole diagnostyczne opisujące tryb pracy CPU |
Wykrycie i lokalizacja błędów funkcjonalnych, nieobsłużonych prawidłowo w programie użytkownika jest trudna i wymaga oprócz sprawnego posługiwania się oprogramowaniem również dokładnej znajomości procesu technologicznego i schematu elektrycznego. Z punktu widzenia sterownika PLC błędy funkcjonalne nie są traktowane jako usterka, stąd też nie są sygnalizowane stanem diod.
Reakcja CPU na błędy systemowe
Wystąpienie błędu systemowego w jednostce centralnej CPU prowadzi do następujących zdarzeń. Do listy informacji statusowych systemu (ang. SSL) wprowadzane są dane o zaistniałym zdarzeniu, takie jak czas i miejsce wystąpienia zdarzenia, typ zdarzenia (błąd synchroniczny/asynchroniczny, zdarzenie generowane przez program użytkownika, zmiana trybu pracy). Informacje diagnostyczne są archiwizowane w CPU i przechowywane w wewnętrznej strukturze danych zwanej buforem diagnostycznym.
Bufor diagnostyczny CPU jest zatem czarną skrzynką procesora i służy do przechowywania meldunków o kolejno zaistniałych i wykrytych przez CPU zdarzeniach. Liczba przechowywanych meldunków jest ograniczona i zależy od typu CPU (np. CPU 314 = 100 wpisów). Bufor diagnostyczny nie jest kasowany w momencie resetu pamięci CPU. Informacje na temat sekwencji wywołań bloków przed zaistnieniem zdarzenia oraz wartości rejestrów CPU i zmiennych lokalnych zapisywane są w tzw. stosach (ang. Stack).
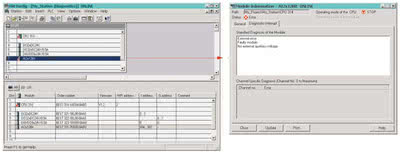
Rys. 2. Edytor konfiguracji sprzętowej – diagnostyka modułów |
System operacyjny CPU wywołuje blok programowy do obsługi wykrytego zdarzenia awaryjnego. Jest to jeden z bloków organizacyjnych OB, o konkretnym numerze np. OB86 (błąd komunikacji ze zdalną kasetą). Zmienne lokalne wywołanego bloku OB są wypełniane informacjami o zaistniałym zdarzeniu awaryjnym. W przypadku wspomnianego bloku OB86 będą to przykładowo: adres kasety, z którą CPU utracił komunikację, stan zdarzenia (przychodzące, odchodzące), data i czas zdarzenia.
W trakcie pracy sterownika mogą wystąpić zdarzenia generowane przez funkcje diagnostyczne modułów I/O, np. wykrycie braku zasilania obiektowego modułu, przerwania toru pomiarowego lub przekroczenie zakresu pomiarowego. Usterka w obrębie modułu I/O przekazywana jest do CPU w formie przerwania diagnostycznego. Sposób przetwarzania przerwań od modułów jest analogiczny jak w przypadku błędów systemowych i logicznych wykrytych przez diagnostykę jednostki centralnej.
Dodatkowe informacje diagnostyczne mogą pochodzić również z programu użytkownika. Są to zgłoszenia diagnostyczne generowane za pośrednictwem funkcji systemowych SFC52. Na rysunku 1 przedstawiony jest sposób diagnostyki błędów systemowych przez sterownik z modułem wejść/wyjść (modułem peryferyjnym) i komunikacja z programatorem. W przypadku nieobsłużenia przez program użytkownika danego zdarzenia diagnostycznego CPU przechodzi samoczynnie w tryb STOP.
Odczytywanie informacji o błędach systemowych
Dokładne informacje o błędzie i miejscu wystąpienia przerwania znajdują się w liście SSL, w buforze diagnostycznym i stosach I stack, B stack, L stack. Właściwe odczytanie powyższych danych umożliwia dokładną lokalizację i określenie przyczyny błędu. Informacje diagnostyczne mogą być odczytane zarówno za pośrednictwem oprogramowania narzędziowego Step 7, jak i przez funkcję systemową SFC51 w programie użytkownika. W artykule omówiono tylko sposób odczytu informacji diagnostycznych z poziomu oprogramowania narzędziowego.
Diagnostyka sprzętowa w edytorze HW Config
Najprostszym sposobem odczytania informacji diagnostycznych jest wykorzystanie edytora konfiguracji sprzętowej HW Config i widoku online. Dane pokazywane są w formie piktogramów i okienek. Za pomocą funkcji diagnostyki sprzętowej można odczytać informacje, między innymi o statusie lub trybie pracy modułu. Otwarcie edytora konfiguracji sprzętowej możliwe jest z poziomu głównego okna Simatic Manager. W tym celu w oknie ze strukturą projektu należy rozwinąć drzewo katalogowe i zaznaczyć wstawioną stację.
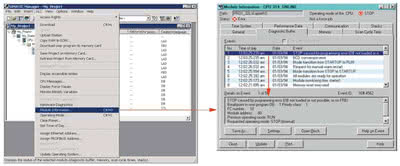
Rys. 3. Wywołanie okna Module Information z informacjami o CPU i modułach |
W polu elementów wybrać Hardware, dwukrotnie klikając jego ikonę lub zaznaczając go i wybierając z menu głównego Edit -> Open Object. Spowoduje to otwarcie okna aplikacji HW Config, która służy do konfigurowania, parametryzacji i diagnostyki sprzętu (rys. 2). Uruchomienie trybu Online następuje po naciśnięciu przycisku Offline/Online znajdującego się w lewym górnym rogu edytora (rys. 2). W oknie aplikacji HW Config przy symbolach dodanych modułów znajdują się symbole diagnostyczne identyfikujące status modułu i tryb pracy CPU. Odpowiednie symbole i ich znaczenie zostały zebrane w tabelach 1 i 2.
Szczegółowa informacja diagnostyczna o CPU i modułach
Dwukrotne kliknięcie symbolu modułu w aplikacji HW Config otwiera okno Module Information z informacjami diagnostycznymi na temat błędnie działającego CPU lub modułu (rys. 3). Okno to wywołać można z następujących lokalizacji:
- W Simatic Manager - poprzez wybór opcji PLC -> Diagnose Hardware w oknie Online view i dwukrotne kliknięcie ikony Hardware wybranej stacji, w HW Config poprzez otwarcie stacji w trybie Online.
- Poprzez wybranie opcji Options -> Customize -> View w Simatic Manager i aktywacji funkcji Display Quick View when Diagnosing Hardware zostanie wyświetlona lista błędnych modułów w oknie Hardware Diagnostics.
Jednostka centralna sterownika PLC ma wbudowane systemowe funkcje diagnostyczne. Nie wymagają one żadnej konfiguracji i programowania przez użytkownika. Taka diagnostyka umożliwia szybką identyfikację, lokalizację oraz późniejszą eliminację błędów. W przypadku jednostki centralnej CPU informacja o module jest znacznie bardziej rozbudowana. Okno z informacjami o systemie jest uruchamiane za pomocą funkcji: PLC -> Module Information (rys. 3).
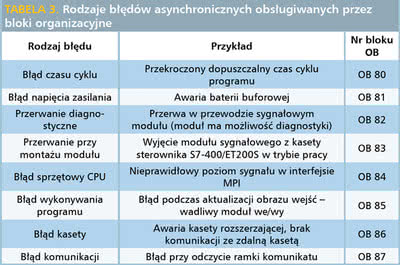
TABELA 3. Rodzaje błędów asynchronicznych obsługiwanych przez bloki organizacyjne |
Dostęp do niej możliwy jest również z poziomu aplikacji Simatic Manager lub edytorów (np. edytor STL/ LAD/FBD). Aplikacja Module Information odczytuje z podłączonego modułu dane diagnostyczne, które grupowane są w określonych zakładkach. Są to:
- General - zawiera podstawowe informacje o module, zainstalowanych wersjach hardware i firmware,
- Diagnostic Buffer - zawiera wszystkie zdarzenia diagnostyczne; w trakcie szukania błędów, po sprawdzeniu meldunków, kolejnym krokiem powinna być właśnie analiza zdarzeń, które są tu pogrupowane w formie listy z opisem tekstowym wyjaśniającym miejsce powstania zdarzenia,
- Memory - zawiera wielkość i wykorzystanie pamięci Load EPROM, Load RAM oraz pamięci Work,
- Scan Cycle Time - czasy cyklu wykonania programu: najkrótszy, najdłuższy oraz aktualny/ostatni,
- Time System - wyświetla zegar czasu rzeczywistego i zintegrowane czasy pracy,
- Performance Data - zawiera informacje o zintegrowanych blokach systemowych, możliwe do przesłania bloki organizacyjne oraz wielkość obszarów adresowania (I, Q, M, T, C, L),
- Communication - wyświetla możliwości komunikacyjne interfejsów oraz zajętość tych połączeń,
- Stacks - wyświetla zawartość stosów: I Stack, B Stack i L Stack. Można je analizować w przypadku, gdy CPU jest w trybie Stop lub jest aktywna funkcja breakpoint. Jest to kolejny, ważny element wyszukiwania błędów systemowych.
Bufor Diagnostyczny
Bufor diagnostyczny (zakładka Diagnostic Buffer aplikacji Module Information) jest to obszar pamięci podtrzymywany bateryjnie lub kondensatorem. Przechowuje on wszystkie zdarzenia diagnostyczne w kolejności wystąpienia ich w systemie. Bufor diagnostyczny nie jest kasowany przy wykonaniu funkcji kasowania pamięci CPU. Wszystkie zdarzenia występujące w tym buforze są wyświetlane w programatorze z opisami tekstowymi (rys. 3).

TABELA 4. Rodzaje błędów synchronicznych obsługiwanych przez bloki organizacyjne |
Po wybraniu określonego zdarzenia w polu Details on Event znajdującym się pod listą wyświetlana jest szczegółowa informacja o zaistniałym zdarzeniu - jego ID, numer zdarzenia, typ i numer bloku oraz dodatkowe informacje zależne od zdarzenia, takie jak adres linii STL, w którym wystąpiło zdarzenie. Dodatkowe pomocnicze informacje o zdarzeniu można wywołać za pomocą przycisku Help on event.
Możliwe jest także przejście do bloku, w którym wystąpiło przerwanie, poprzez kliknięcie Open block. Blok zostanie otwarty w trybie online. W języku STL kursor edytora ustawia się w pozycji bezpośrednio przed instrukcją generującą błąd. W przypadku języka LAD/FBD wyświetlana jest linia (network) zatrzymania przetwarzania programu.
Bloki organizacyjne do obsługi błędów
Z błędami systemowymi powiązane są specjalne bloki organizacyjne, w których użytkownik/programista może umieścić swój program do obsługi określonej usterki. Bloki organizacyjne wywoływane są w następstwie wykrycia przez CPU tzw. błędów asynchronicznych lub synchronicznych. Błędy asynchroniczne są związane z problemami w funkcjonowaniu sterownika, które mogą pojawić się w dowolnym miejscu programu, tak więc są asynchroniczne względem jego wykonywania.
Spis bloków związanych z błędami asynchronicznymi znajduje się w tabeli 3. Błędy synchroniczne są synchroniczne względem wykonywanego programu, czyli występują stale w tym samym miejscu programu użytkowego. One także mogą być obsłużone przez odpowiednie bloki organizacyjne z tabeli 4.
Analiza stosów
 W przypadku błędów synchronicznych (OB 121, OB 122) ma sens wyświetlenie dodatkowych informacji o tym, co było powodem powstania błędu i zatrzymania przetwarzania programu. Takie informacje przechowywane są w stosach (I stack, B stack, L stack).
W przypadku błędów synchronicznych (OB 121, OB 122) ma sens wyświetlenie dodatkowych informacji o tym, co było powodem powstania błędu i zatrzymania przetwarzania programu. Takie informacje przechowywane są w stosach (I stack, B stack, L stack).
Aby informacje zostały zapisane w stosach, CPU musi przejść w tryb STOP. Może się to zdarzyć tylko wtedy, gdy wystąpił błąd programowy, programowe przełączenie w tryb STOP (poprzez funkcję SFC) lub została załączona funkcja breakpoint.
- Stos B (B stack) - nazywany stosem bloków, jest podstawowym stosem widocznym w zakładce Stacks okna Module Information (rys. 3). Stos B zawiera listę wywoływanych bloków, które zostały otwarte w momencie przejścia CPU w tryb Stop, i jest przedstawiany w postaci graficznej hierarchii wywołań bloków do momentu zatrzymania przetwarzania programu. Podczas analizy stosu B należy zwrócić uwagę na blok umieszczony na końcu listy, ponieważ zostało w nim zatrzymane przetwarzanie programu. Stos B zawiera zatem listę wszystkich przerwanych bloków, bloki OB błędów oraz otwarte bloki DB. W celu otwarcia bloku online należy otworzyć stos B, następnie wybrać blok z listy oraz otworzyć edytor przyciskiem Open Block. W edytorze kursor od razu ustawi się w miejscu zatrzymania programu. Może być także potrzebna dokładniejsza analiza kolejnych bloków, ponieważ bloki są często w różnych miejscach wywoływane w programie sterowania. Informacja, która instrukcja i w jakim bloku przerywa przetwarzanie programu, nie wystarcza do znalezienia miejsca powstania błędu.
- Stos I (I Stack) - jest nazywany także stosem przerwań. Stos przerwań przechowuje informacje o przerwaniach w odniesieniu do poziomu wykonywania przetwarzania programu. Otwiera się go w zakładce Stacks, zaznaczając odpowiedni blok organizacyjny w stosie B i klikając I Stack (rys. 4). Stos I zawiera wartości rejestrów systemowych w momencie wystąpienia przerwania. W polu Register Values and the Point of Interruption znajduje się zawartość akumulatorów i rejestrów adresowych oraz zawartość słowa statusu (bity 0 do 7). Za pomocą listy Display Format można wybrać format liczby do wyświetlenia zawartości akumulatorów i rejestrów adresowych. W polu Point of Interruption znajdują się informacje, jakie bloki danych zostały otwarte, jaki był przetwarzany program (np. OB 1 lub OB 10), informacja o bloku, w którym wystąpiło przerwanie z opcją bezpośredniego otwarcia oraz informacja o następnym przetwarzanym bloku. W tym oknie są wyświetlane bity 0 do 7 słowa statusu.
- Stos L (L Stack) - nazywany jest także stosem lokalnym. Otwiera się go w zakładce Stacks, zaznaczając odpowiedni blok organizacyjny w stosie B i klikając przycisk L Stack (rys. 4). W stosie L znajdują się wartości zmiennych tymczasowych niedokończonych w momencie przerwania dla całego bloku przedstawione w formacie szesnastkowym. Bloki niedokończone w momencie przejścia CPU w tryb STOP znajdują się w liście stosu bloków (B Stack).
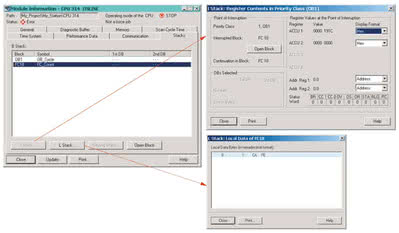
Rys. 4. Podgląd stosów – B stack, I stack, L stack |
Podsumowanie
Znajomość i umiejętne zastosowanie funkcji diagnostycznych znacznie ułatwia wykrycie i eliminację błędów aplikacji. W artykule opisano rodzaje błędów, jakie mogą wystąpić podczas pracy sterownika PLC Simatic firmy Siemens. Dokonano podziału na błędy systemowe i funkcjonalne. Opisano również sposób pracy z aplikacjami diagnostycznymi środowiska Step 7 pomagającymi w identyfikacji błędów systemowych.
Są to podstawowe elementy diagnostyki sterownika, ponieważ już na etapie pracy CPU można dokładnie zidentyfikować zaistniałe problemy i je wyeliminować. W kolejnym artykule z tej serii zostanie przedstawiony sposób wykrywania błędów funkcjonalnych, które na etapie samej aplikacji mogą nastręczać wielu poważnych problemów i są trudniejsze do wykrycia niż błędy systemowe.
Jakub Możaryn
Wojciech Kuś
Siemens
www.siemens.automatykab2b.pl











