
Szkolenia w zakresie Przemysłu 4.0 można podzielić na dwie grupy. Pierwszą stanowią kursy, które ogólnie omawiają tę koncepcję i zbiorczo przedstawiają nowe technologie, które są zaliczane do tej kategorii. Zwykle na wstępie tego typu szkoleń podawane są definicje Industry 4.0 i Smart Factory. Potem wyjaśniane są kluczowe pojęcia jak systemy cyberfizyczne. Prezentuje się również założenia czwartej rewolucji przemysłowej, z reguły w odniesieniu do wcześniejszych punktów zwrotnych w historii przemysłu.
Koncepcja Przemysłu 4.0 jest następnie przedstawiana z perspektywy technicznej i ekonomicznej. Oznacza to omówienie technologii stanowiących trzon Industry 4.0, czyli: Big Data, wirtualnej i rozszerzonej rzeczywistości, uczenia maszynowego / sztucznej inteligencji, chmury obliczeniowej, robotów współpracujących (cobotów), druku 3D, Przemysłowego Internetu Rzeczy, blockchainu i cyfrowych bliźniaków oraz prezentację modeli biznesowych cyfrowej transformacji przedsiębiorstw produkcyjnych.
Przy tej okazji wyjaśniane są wyzwania towarzyszące wdrażaniu nowych technologii w praktyce. Te ostatnie przedstawia się zwykle na przykładach rzeczywistych realizacji. Wśród zagadnień, które są typowo poruszane na tego typu szkoleniach, można także wymienić zarządzanie kompetencjami pracowników w dobie Industry 4.0 i zagrożenia cyberbezpieczeństwa w systemach przemysłowych. Drugą grupę szkoleń stanowią te dotyczące konkretnych technologii.
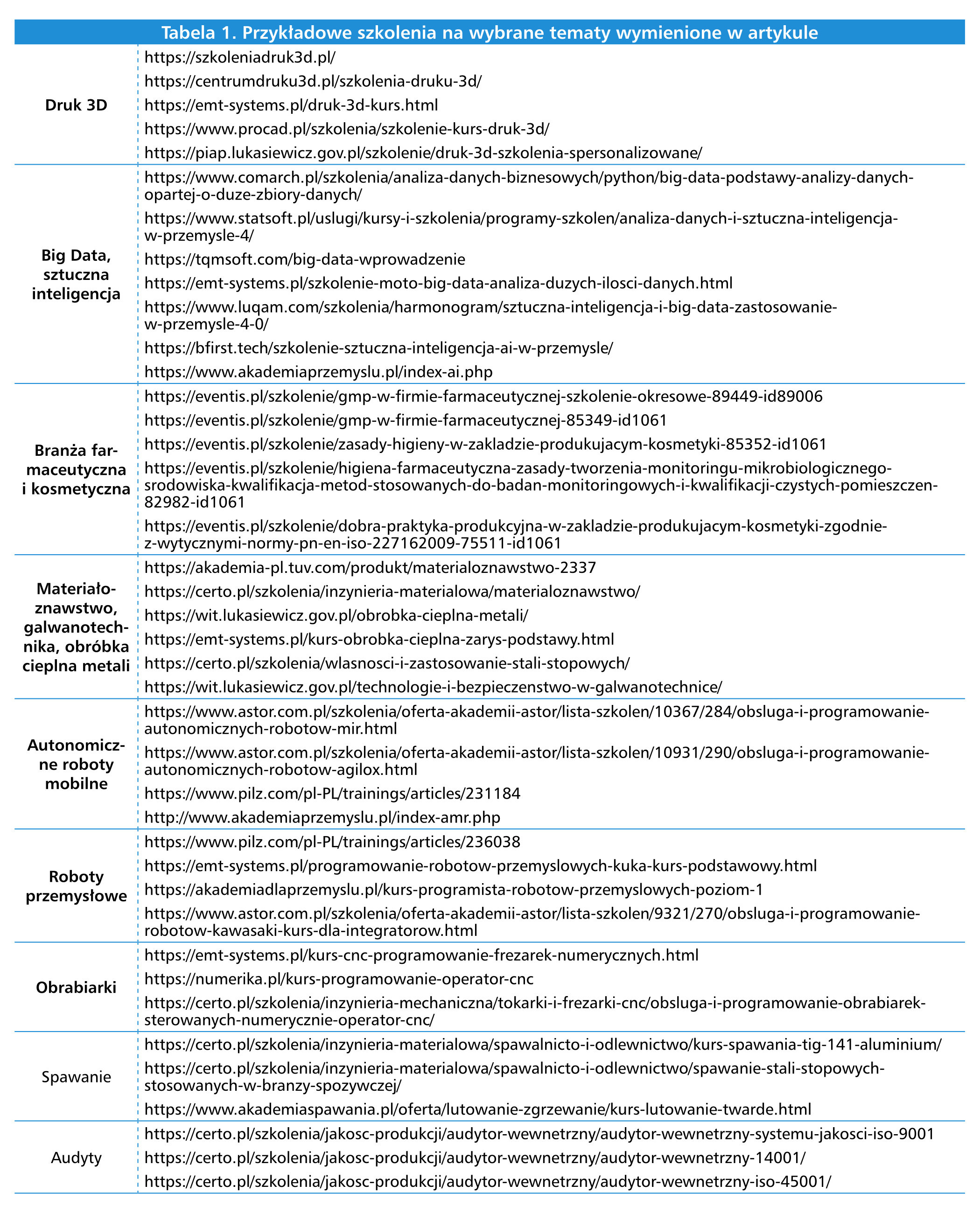
Szkolenia z druku 3D
Przykładem są te poświęcone wytwarzaniu addytywnemu. W tej grupie wyróżnia się trzy kategorie szkoleń: wprowadzające do techniki druku 3D, przedstawiające specyfikę poszczególnych metod wytwarzania oraz teoretyczno-praktyczne z obsługi drukarek 3D i ich oprogramowania.
We wszystkich przeważnie na początku przedstawia się podstawy technologii przyrostowych i ich porównanie z innymi (ubytkowymi, odlewami). Następnie charakteryzuje się oraz ze zestawia sobą różne metody zaliczane do kategorii druku 3D. Te zazwyczaj klasyfikuje się ze względu na rodzaj materiału, z którego w danej technologii można wykonać wydruk.
Niektóre firmy szkoleniowe poświęcają tej tematyce oddzielne kursy. Szczegółowo omawia się na nich m.in. metody druku z: metali, na przykład z proszków w technice laserowej, elektronowej i chemiczno- termicznej, z prętów oraz drutu przez napawanie, ekstruzję albo techniki hybrydowe, łączące druk 3D z obróbką CNC, z tworzyw sztucznych termoplastycznych metodami FDM (Fused Deposition Modeling) i FFF (Fused Filament Fabrication) oraz z żywic światłoutwardzalnych, w technice stereolitografii.
W zakresie korzystania z drukarek 3D zwykle prezentowane tematy to z kolei: zasady eksploatacji (przygotowanie do druku, wyjęcie wydruku) i konserwacji, częste problemy oraz ich rozwiązania, zarządzanie drukowaniem z wielu drukarek i na urządzeniach wielogłowicowych. Organizowane są zarówno kursy z ogólnej obsługi tych urządzeń, jak i korzystania z drukarek konkretnych marek. Prezentowane jest także oprogramowanie tnące i sterujące. Dodatkowo charakteryzowane są różne techniki oraz trendy w obróbce wykończeniowej gotowych wydruków 3D.
Szkolenia z obsługi AMRNa kursach z obsługi autonomicznych robotów mobilnych zazwyczaj przestawiane są następujące zagadnienia: budowa AMR od strony praktycznej (napęd, zasilanie, czujniki), tryby pracy, obsługa AMR za pośrednictwem dostępnego interfejsu, tworzenie map, dodawanie stref oraz punktów, projektowanie misji, analiza i monitorowanie pracy AMR, obsługa błędów. Ponadto omawiane są: praca robotów we flotach, systemy zarządzania energią, wymagania środowiskowe, warunki oraz parametry ładowania, bezpieczeństwo użytkowania. Zwykle prowadzący wyjaśniają też, jak wybrać najlepszy do danych wymagań model AMR, kiedy wykorzystać konwencjonalne rozwiązania transportowe (przenośniki), a kiedy zastąpić je autonomicznymi robotami mobilnymi oraz przedstawiają przykłady rozwiązań systemów autonomicznego transportu wewnętrznego. 
|
Wprowadzenie do Big Data

Kursy poświęcone tytułowemu zagadnieniu zazwyczaj rozpoczynają się od przedstawienia definicji dużych zbiorów danych i ich historii. W ramach wprowadzenia charakteryzuje się też specyfikę Big Data oraz możliwości wynikające z analizy dużych zbiorów danych i wyzwania towarzyszce ich obróbce. Obowiązkowym punktem na wstępie jest oprócz tego przegląd zastosowań Big Data w różnych dziedzinach w zakresie wykrywania zależności i ukrytych przyczyn – wykorzystuje się je m.in. w predykcyjnym utrzymaniu ruchu i przewidywaniu wyników procesów produkcyjnych i ich optymalizacji. Uzupełnieniem tych informacji jest zwykle charakterystyka popularnych technologii i narzędzi do przechowywania, przetwarzania i analizy dużych zbiorów danych, takich jak: Hadoop, Spark, NoSQL czy Kafka.
W kursach zaawansowanych szczegółowo omawia się poszczególne etapy obróbki Big Data. Takim jest zbieranie oraz przechowywanie danych, w zakresie którego przedstawiane są różne podejścia do gromadzenia oraz przechowywania informacji, takie jak relacyjne i nierelacyjne bazy danych. W zakresie przetwarzania danych prezentuje się zwykle techniki wstępnej obróbki oraz wyjaśnia się różnice między przetwarzaniem wsadowym i strumieniowym. Jeżeli chodzi o etap wizualizacji i analizy danych, program szkoleń z zakresu Big Data z reguły obejmuje wprowadzenie do metod i narzędzi, które są w tym zastosowaniu popularne – omawiane są standardowo algorytmy uczenia maszynowego i techniki eksploracji danych. Wśród zagadnień, które są typowo poruszane na tego typu szkoleniach, można również wymienić wyzwania związane ze skalowalnością i wydajnością systemów Big Data oraz bezpieczeństwo i prywatność danych.
Patrycja Jasińska
|

Szkolenia z AI i cyfrowych bliźniaków
W ramach kursów poświęconych ogólnie Przemysłowi 4.0, jak i tych szczegółowych dotyczących Big Data, zwykle poruszany jest temat sztucznej inteligencji. Przedstawiane są kluczowe pojęcia z tej dziedziny, jak uczenie maszynowe, sztuczne sieci neuronowe czy deep learning (uczenie głębokie) oraz omawiane są podstawowe zagadnienia z zakresu wykorzystania AI, w tym przygotowanie danych, tworzenie na ich podstawie modeli i ich trenowanie. Podawane są ponadto przykłady wykorzystania sztucznej inteligencji w przemyśle w optymalizacji procesów, na przykład w celu poprawy efektywności energetycznej czy ograniczenia przestojów dzięki podejściu predykcyjnemu w utrzymaniu ruchu.
Ważną częścią Industry 4.0 są cyfrowe bliźniaki, czyli wirtualne reprezentacje lub repliki obiektów albo produktów, które wykorzystuje się w symulacjach w celu przewidywania przebiegu procesów albo zmian właściwości. Na szkoleniach w ramach wprowadzenia do tej technologii zazwyczaj przedstawia się jej podstawy (główne koncepcje, terminy, historię), charakteryzuje typy cyfrowych bliźniaków i ich główne bloki funkcyjne, omawia cykl życia i przypadki użycia oraz popularne platformy.

Szkolenia branżowe

Wyróżnia się też szkolenia dla konkretnych branż. Przykład to te dla przemysłu farmaceutycznego i kosmetycznego. Ze względu na ich specyfikę dotyczą głównie norm sanitarnych, które obowiązują w zakładach o takim profilu produkcji. W szkoleniach z zasady, higieny typowo poruszane są takie kwestie jak: wymagania dotyczące stanu pomieszczeń i maszyn, utrzymanie ich czystości, higiena personelu, zagrożenia w procesie produkcji, strefy ryzyka i przepisy w zakresie GMP, czyli Dobrej Praktyki Produkcyjnej. Tej ostatniej poświęcone są również oddzielne szkolenia, w ramach których przedstawiane są przepisy i zasady nadzoru ich przestrzegania.
Prowadzone są oprócz tego kursy dotyczące wytycznych konkretnych norm, na przykład PN-EN ISO 22716 określającej dobre praktyki w produkcji, kontroli, składowaniu i transporcie produktów kosmetycznych. Omawia się na nich: zasady tworzenia dokumentacji GMP w zakładzie o takim profilu produkcji (zapisy księgi GMP, instrukcje, procedury i formularze), wyznaczanie i znakowanie stref brudnych i czystych, określanie punktów kontrolnych w procesie produkcyjnym, zagrożenia mikrobiologiczne i ich przyczyny specyficzne dla produkcji kosmetyków, zasady postępowania i dokumentacji wyrobów niezgodnych, tworzenie dokumentacji i audyty.
W ofercie firm szkoleniowych można oprócz tego znaleźć kursy o zawężonej tematyce, na przykład dotyczące zagrożeń mikrobiologicznych na liniach technologicznych w branży farmaceutycznej i kosmetycznej. W ich programie poruszane są: zasady organizacji monitoringu mikrobiologicznego, procedury kontroli mikrobiologicznej konkretnych pomieszczeń produkcyjnych i laboratoryjnych, metody sprawdzania czystości mikrobiologicznej powierzchni, przykłady harmonogramów prób czystości powierzchni, pomieszczeń, maszyn, personelu i dokumentacja kontroli mikrobiologicznej.
Obsługa i konserwacja urządzeń transportuDo tytułowej grupy można zaliczyć kursy operatorów suwnic. W ramach szkoleń tego typu omawia się m.in.: podstawowe wiadomości o suwnicach, w tym ich podział, budowę, parametry techniczne, stosowane w nich urządzenia zabezpieczające, sterownicze, sygnalizacyjne, zawiesia i ich nośność, osprzęt roboczy, zasady bezpiecznej eksploatacji suwnic, kwalifikacje operatorów i konserwatorów. Kolejne przykłady to kursy operatorów podestu ruchomego przejezdnego oraz obsługi żurawi stacjonarnych. W ramach szkoleń tego typu przedstawiane są podobne zagadnienia co w przypadku suwnic z uwzględnieniem specyfiki podestów i żurawi. Przykładem szkoleń stanowiskowych są też kursy dla konserwatorów suwnic, wciągników oraz wciągarek. Tematy podczas nich poruszane to m.in.: ogólne wiadomości o dozorze technicznym, dotyczące go normy, przepisy, regulacje prawne, budowa i eksploatacja suwnic, wciągników i wciągarek podlegających dozorowi technicznemu, ich instrukcje obsługi oraz dokumentacja techniczno-ruchowa, obowiązki i uprawnienia konserwatora (przeglądy i naprawy), plan konserwacji, zasady prowadzenia książki konserwacji i obsługi, typowe usterki i sposób ich usuwania. 
|
Szkolenia tematyczne
Do tytułowej kategorii zaliczane są szkolenia z materiałoznawstwa. Typowo przypomina się na nich niezbędne wiadomości z fizyki i chemii (m.in. budowę atomu, rodzaje wiązań międzyatomowych, budowę sieci krystalograficznych), przedstawia się różne rodzaje materiałów (metale i ich stopy, polimery, materiały ceramiczne, kompozyty), charakteryzuje właściwości fizyczne, chemiczne oraz mechaniczne wybranego albo kilku materiałów, na przykład metali i ich stopów oraz metody ich produkcji i obróbki (na przykład proces wytwarzania stali, rodzaje obróbki plastycznej i cieplnej metali) i omawia niszczący wpływ czynników środowiskowych (korozję). Prowadzone są również szkolenia szczegółowe, poświęcone konkretnym typom materiałów i metodom ich obróbki.

Przykładowo na kursie dotyczącym stali stopowych (nierdzewnych) poruszane są zazwyczaj takie kwestie jak: właściwości tych materiałów, ich spawanie i obróbka mechaniczna, korozja i ochrona przed nią, konserwacja i eksploatacja, zastosowanie stali stopowych oraz ich najpopularniejsze typy jak: stal austenityczna, ferrytyczna, martenzytyczna, duplex.
Nie brakuje też szkoleń na temat obróbki materiałów. Przykładem są te z zakresu obróbki cieplnej metali. Omawia się na nich zazwyczaj: mechanizmy, jakie zachodzą pod wpływem oddziaływania termicznego, najpopularniejsze metody (hartowanie, wyżarzanie, przesycanie, starzenie), zasady doboru konkretnej techniki do wymaganych właściwości materiału, zmiany struktury i właściwości metali po obróbce cieplnej w oparciu o przemiany fazowe i strukturalne.
Kolejnym przykładem są szkolenia z zakresu galwanotechniki. W ramach kursów tego typu zwykle przedstawia się tematy takie jak: najważniejsze pojęcia i podstawy procesów galwanotechnicznych, metody przygotowania powierzchni, popularne metody obróbki galwanotechnicznej (cynkowanie, niklowanie, srebrzenie, złocenie, palladowanie, rodowanie, platynowanie, anodowanie, barwienie aluminium, chromowanie, miedziowanie) oraz techniki badania jakości powłok.
Jadwiga Woźnik
|

Szkolenia z robotów przemysłowych

Ważną kategorią są szkolenia z zakresu obsługi konkretnych typów urządzeń. Przykładem są kursy korzystania z robotów przemysłowych.
Szkolenia tego typu zazwyczaj dotyczą maszyn konkretnej marki. Mają kilka grup docelowych. Zainteresowani nimi są użytkownicy, programiści oraz integratorzy robotów przemysłowych, jak i osoby odpowiedzialne za utrzymanie ruchu w zakładzie. W zależności od tego różnią się poruszaną tematyką. W przypadku kursów dla użytkowników na wstępie podaje się informacje podstawowe, m.in. na temat budowy i parametrów robotów. Bez względu na stopień zaawansowania kursantów standardowo w ramach tego rodzaju szkoleń przedstawiane są zagrożenia oraz zasady bezpiecznej pracy. Użytkownikom wyjaśnia się też, jak podłączyć, uruchomić i wyłączyć robota i wprowadza w podstawy jego programowania online/offline. Na szkoleniach dla integratorów rozszerza się te zagadnienia oraz uzupełnia je o informacje pomocne w integrowaniu oraz wdrażaniu stanowiska zrobotyzowanego, zaś służbom utrzymania ruchu przybliża się kwestie związane z przeglądami okresowymi i codziennymi, resetowaniem robota, aktualizacją oprogramowania i przede wszystkim obsługą błędów. Oprócz szkoleń z zakresu obsługi tradycyjnych robotów przemysłowych można znaleźć coraz więcej kursów poświęconych nowym rozwiązaniom, takim jak roboty współpracujące czy autonomiczne roboty mobilne (patrz: ramka).
Jacek Gurzyński
|

Obsługa obrabiarek
Przykładem są też kursy obsługi i programowania obrabiarek sterowanych numerycznie. Ich grupą docelową są operatorzy i programiści CNC. Zazwyczaj na początkowych zajęciach przedstawiane są podstawy rysunku technicznego w obróbce skrawaniem. Następnie charakteryzowane są techniki obróbki. Wybrane tematy poruszane na tym etapie to: budowa i kinematyka tokarki / frezarki, typy narzędzi tokarskich i frezarskich oraz ich charakterystyka, materiały do produkcji narzędzi skrawających i ich charakterystyka, geometria tokarki / frezarki i jej punkty charakterystyczne, układ współrzędnych przedmiotu obrabianego. W temacie programowania obrabiarek CNC omawiane są z kolei m.in. następujące zagadnienia: interpolacje liniowe oraz kołowe i tworzenie programów w znormalizowanym języku zapisu poleceń dla urządzeń CNC (G-code).
Na zajęciach praktycznych natomiast zwykle przedstawia się podstawy pracy z konkretnymi modelami centrów obróbczych z różnymi sterownikami, w tym: uruchamianie maszyny, jej inspekcję i konserwację, mocowanie narzędzi oraz przedmiotów obrabianych. Przeważnie na szkoleniach ogólnych w części praktycznej kursanci mają do dyspozycji obrabiarki ze sterownikami marek popularnych w branży CNC, z którymi najprawdopodobniej zetkną się w pracy (Sinumerik, FANUC, Okuma, Heidenhain). Ponadto prowadzone są szkolenia poświęcone sprzętowi konkretnych producentów. Osoby szkolące się z technologii obróbki skrawaniem mogą też zainteresować kursy dla programistów CAD/ CAM, na których nauczą się m.in. przygotowywać modele pod kątem toczenia i frezowania.

Szkolenia stanowiskowe
Bogata jest także oferta szkoleń dla konkretnych stanowisk pracy. Przykładem są te dla spawaczy. Zainteresowani tą profesją mogą wziąć udział m.in. w kursach, na których poznają podstawy tej techniki. Omawia się na nich zwykle: klasyfikację metod łączenia metali (spawanie, zgrzewanie, lutowanie) i procesów spawania, spawalność różnych materiałów, przyczyny odkształceń części spawanych i sposoby ich ograniczania, techniki przygotowania krawędzi blach, wpływ różnych parametrów na proces spawania, pozycje spawania, rodzaje i wymiarowanie spoin, typy pęknięć w złączach spawanych (gorące, zimne, lamelarne, wyżarzeniowe). Zainteresowani mogą także wziąć udział w kursach poświęconych normom branżowym, na przykład serii PN-EN 15085 dotyczącej spawania części pojazdów szynowych, zasadom projektowania konstrukcji spawanych i obliczania kosztów procesu spawania.
Na kursach z projektowania konstrukcji spawanych omawia się tematy takie jak: podstawy obliczeń konstrukcyjnych i obliczania spoin, oznaczanie spoin na rysunkach, zachowanie się złączy spawanych przy różnego rodzaju obciążeniach (statyczne, dynamiczne, przełomy), obciążenia dynamiczne i termomechaniczne w konstrukcjach spawanych. Na kursach poświęconych kosztom spawania przedstawia się z kolei: ich główne składniki, zasady obliczania ilości materiałów dodatkowych (drutu, elektrod, gazu, topników), czasu spawania, współczynnika czasu jarzenia łuku, kosztów robocizny, materiałów dodatkowych, energii elektrycznej, amortyzacji urządzeń spawalniczych. Przedstawia się dodatkowo zwykle porównanie kosztów różnych metod spawania i materiałów dodatkowych oraz sposoby na ich ograniczanie.
Na oddzielnych kursach od strony teoretyczno-praktycznej można się ponadto zapoznać z różnymi metodami spawania, na przykład elektrodą otuloną, topliwą w osłonie gazów, nietopliwą w osłonie gazów, łukiem krytym. Innym przykładem szkoleń stanowiskowych są kursy obsługi urządzeń transportu bliskiego (patrz: ramka).
Mariusz Michalski
|

Szkolenia z BHP
Do oddzielnej kategorii zaliczyć można szkolenia, które zwiększają ogólną świadomość w zakresie przepisów interesujących różne branże. Do takich należą szkolenia z BHP.
Ich uczestnicy zaznajamiani są z przepisami i ogólnymi wymogami dotyczącymi pracy w warunkach o podwyższonym ryzyku. Poznają różne typy zajęć niebezpiecznych, jak: praca na wysokości, pod napięciem, w pomieszczeniach zamkniętych, korzystanie z narzędzi i maszyn, w tym z ruchomymi elementami, kontakt z substancjami niebezpiecznymi i zagrożenie wybuchem i pożarem. Typowo w ramach tych kursów omawiane jest także oznakowanie na stanowiskach pracy informujące o zagrożeniach na nich występujących i stosowane środki ochrony indywidualnej. Ważnym tematem jest ponadto ocena ryzyka zawodowego. W ramach zajęć jej poświęconych zwykle przedstawiane są, oprócz podstaw prawnych, tematy takie jak: sposoby identyfikacji zagrożeń, metody szacowania poziomu ryzyka zawodowego, środki je zmniejszające i sposoby ostrzegania personelu przed rozpoznanym niebezpieczeństwem i poszerzania jego świadomości na ten temat.
Prowadzone są także szkolenia ze specyfiki BHP na konkretnych stanowiskach pracy, na przykład dla operatorów maszyn. Przykładem szkoleń o zawężonej tematyce są również kursy dla audytorów różnych norm (patrz ramka).
Formy szkoleń
Szkolenia mogą mieć różną formę. Najpopularniejsze z nich to: teoretyczne, praktyczne, zamknięte i otwarte. W pierwszych zajęcia mają charakter wykładu, obecnie zwykle w formie prezentacji multimedialnej. Praktyczne z kolei odbywają się najczęściej w laboratorium, gdzie kursanci mają okazję przećwiczyć i utrwalić zdobytą wiedzę, pojedynczo albo pracując w grupach, na maszynach i sprzęcie związanym z tematem kursu.
W przypadku szkoleń, w których praktyka ma kluczową rolę w przyswojeniu informacji teoretycznych, wybierając firmę szkoleniową, warto sprawdzić jej ofertę również pod kątem wyposażenia stanowisk do ćwiczeń. Ważna jest jego różnorodność, co pozwoli na nabycie doświadczenia na sprzęcie różnych producentów, jeżeli szkolenie nie dotyczy urządzeń konkretnej marki, nowoczesność i zgodność z najnowszymi standardami branżowymi. Istotne jest również to, kto będzie prowadził szkolenia – w tych dla przemysłu doświadczenie w stosowaniu albo wdrażaniu danego rozwiązania jest bowiem równie ważne, jak wiedza teoretyczna na jego temat.
Szkolenia zamknięte i otwarte
Szkolenia zamknięte zazwyczaj realizowane są dla grup kilku–kilkunastoosobowych, przeważnie pracowników tego samego przedsiębiorstwa albo członków tej samej organizacji. Ich program, forma, czas trwania oraz liczebność grup są przeważnie dostosowane do zadeklarowanych potrzeb uczestników. Oprócz tego miejsce i terminy zajęć ustalane są indywidualnie.
Tego rodzaju kursy najbardziej opłaca się wybrać, jeżeli przeszkolonych ma zostać więcej osób. Czasem też wymagać tego może specyfika zagadnienia będącego tematem zajęć. Przykładowo zdarza się, że organizacja szkolenia zamkniętego na życzenie jest jedyną opcją, jeśli trzeba usystematyzować, poszerzyć albo zaktualizować wiedzę pracowników na temat, który w ich pracy jest niezbędny, lecz generalnie jest niszowy i z powodu jego małej popularności w tym zakresie nikt powszechnie nie szkoli.
Poza tym, jeżeli w czasie kursu będą poruszane kwestie poufne, jak tajemnice handlowe czy zastrzeżone szczegóły rozwiązań technicznych, podczas szkolenia zamkniętego łatwiej o zachowanie tajemnicy. Z drugiej strony jednak ta forma jest zwykle nieopłacalna przy małej liczbie kursantów. Liczyć się trzeba też z tym, że nie będzie możliwa wymiana doświadczeń z osobami spoza danej organizacji.
Szkolenia otwarte też mają zalety i wady. Jeżeli chodzi o pierwsze najważniejsze, to zwykle niższy koszt i opłacalność nawet w przypadku oddelegowania na kurs kilku osób, większa różnorodność tematów do wyboru i, ponieważ w szkoleniu uczestniczą pracownicy i przedstawiciele różnych firm i organizacji, możliwość nawiązania nowych kontaktów biznesowych oraz wymiany doświadczeń zawodowych. Z drugiej strony liczyć się trzeba z takimi ograniczeniami, jak ustalone na "sztywno": termin, miejsce i czas trwania szkolenia, co wiąże się z dodatkowymi wydatkami na przejazd, nocleg i wyżywienie, jak i program. To ostatnie bywa problemem, bo tematyka kursów otwartych z konieczności jest zwykle ogólna i często uproszczona, by materiał był zrozumiały dla wszystkich uczestników, którzy mogą się w różnym stopniu w danym zagadnieniu orientować.
Szkolenia dla audytorówPrzykładem szkoleń z tytułowej kategorii są kursy audytorów wewnętrznych systemu zarządzania środowiskowego ISO 14001. W ich ramach przedstawiane są typowo takie zagadnienia jak: cele i korzyści z zarządzania środowiskowego, aktualne regulacje prawne i wymogi związane z ochroną środowiska, wprowadzenie do normy ISO 14001, interpretacja jej wymagań z perspektywy audytora wewnętrznego, kluczowe koncepcje i terminologia, związane z normą, rola audytora wewnętrznego, wymagania dotyczące jego kompetencji, jego typowe zadania. W czasie szkoleń dla audytorów systemu zarządzania bezpieczeństwem i higieną pracy ISO 45001 omawiane są z kolei przeważnie następujące tematy: historia i struktura normy ISO 45001, omówienie jej wymagań, podstawy BHP, rola i odpowiedzialność pracowników i planowanie działań, które będą zapobiegać wypadkom i chorobom zawodowym, wymagania dotyczące oceny efektów działań, zarządzania zasobami oraz działań operacyjnych. Na szkoleniach dla audytorów systemu zarządzania jakością ISO 9001 natomiast porusza się takie kwestie, jak: charakterystyka systemu zarządzania jakością, jego planowanie, zakres zadań audytu i uprawnienia audytora, planowanie audytu. 
|
Szkolenia online
Choć pandemię mamy za sobą, przeglądając ofertę firm szkoleniowych, można zauważyć, że na stałe weszły do niej kursy w wersji online, które często są dostępne nawet wówczas, gdy dane szkolenie jest również prowadzone w wersji tradycyjnej, stacjonarnej. Ich zaletą jest możliwość odbycia kursu w zaciszu domowym albo w biurze, bez konieczności przemieszczania się, z czym zawsze wiąże się jakaś strata sił i czasu. Co więcej, biorąc udział w szkoleniu zdalnym, łatwiej jest o skupienie, jeśli normalnie rozprasza nas obecność innych osób, które na przykład w sali, siedząc za nami, mogą wymieniać między sobą uwagi.

Organizatorzy szkoleń online starają się też stwarzać uczestnikom namiastkę tych "prawdziwych" , organizując wydarzenia live. W ich trakcie uczestnicy mają podgląd na salę wykładową, widząc i słysząc, co się dzieje, a jednocześnie śledząc na ekranie treści prezentowane przez prowadzącego. Aby kursy na żywo online w porównaniu ze stacjonarnymi nie wypadały gorzej, zapewnia się też ich użytkownikom możliwość interakcji. Dzięki temu mogą zadawać pytania oraz uczestniczyć w dyskusji pomiędzy prowadzącymi i innymi uczestnikami. Poza tym wykorzystuje się symulacje i techniki zdalnego dostępu pozwalające na wykonywanie ćwiczeń w warunkach jak najbardziej zbliżonych do rzeczywistych.
Nowe technologie w szkoleniach
To ostatnie pomagają zapewnić nowoczesne technologie, przede wszystkim wirtualną rzeczywistość i cyfrowe bliźniaki. Dzięki nim pracowników można szkolić w realistycznych oraz interaktywnych środowiskach będących wirtualnymi reprezentacjami rzeczywistych obiektów, maszyn i procesów, które symulują konkretne miejsca pracy. Niektóre firmy szkoleniowe oferują też spersonalizowane kursy, z modułami, w których uczestnicy szkolą się w środowisku będącym cyfrowym bliźniakiem autentycznych części zakładu kursantów, które przeniesiono do wirtualnej rzeczywistości przez ich wcześniejsze zeskanowanie.

Podczas szkoleń w tej formie kursant korzysta z gogli i joysticka, które odseparowują go od bodźców zewnętrznych i umożliwiają interakcję z elementami cyfrowo wykreowanej przestrzeni, którą zostaje otoczony. Szkolenia w wirtualnej rzeczywistości pozwalają pracownikowi w bezpieczny i powtarzalny sposób przećwiczyć procedury i schematy działania na podobieństwo szkoleń w symulatorach. Ich zaleta to również możliwość przeszkolenia dużej liczby pracowników w szybki i efektywny sposób.
W ten sposób realizowane są różne scenariusze ćwiczenia umiejętności i reagowania na sytuacje, które mogą wystąpić na co dzień lub w sytuacjach nietypowych. Przykładowo w ten sposób można zaznajomić nowo zatrudniane osoby z zakładem, zapoznając je z rozkładem pomieszczeń, dzięki czemu dowiedzą się, jak się po nich poruszać, żeby uniknąć zagrożeń. Dzięki temu, że taki spacer będzie się odbywał w rzeczywistości wirtualnej, pracownik pozostanie odizolowany od realnego zagrożenia, a jednocześnie nie będzie konieczności wstrzymania produkcji ani w nią ingerowania. Pozwala to również zaoszczędzić czas.
Podobnie skuteczne są szkolenia z obsługi maszyn, które pozwalają na bezpieczne eksperymentowanie i uczenie się bez ryzyka dla zdrowia lub mienia. To ważne zwłaszcza w przypadku kursów związanych z użytkowaniem urządzeń niebezpiecznych albo korzystaniem z substancji szkodliwych dla zdrowia. W tej formie przeprowadza się również szkolenia BHP. Pozwalają one pracownikowi w bezpieczny i powtarzalny sposób przećwiczyć procedury i schematy działania w wirtualnym zakładzie. W ten bezstresowy sposób szybciej przyswaja on informacje i lepiej zapamiętuje kroki postępowania, dzięki czemu później, już w sytuacjach stresowych, popełnia mniej błędów.
Monika Jaworowska

















