
Jeżeli chodzi o grupę najbardziej perspektywicznych zastosowań Internetu Rzeczy słowo klucz to predykcja, czyli przewidywanie. Wyróżnia się dwa kierunki wykorzystania w tym celu danych z systemów zdalnego monitoringu przesyłanych w sieciach IoT. Pierwszym jest poprawa jakości produkcji, natomiast drugim - eliminacja przestojów.
KONTROLA JAKOŚCI - OBECNIE...
 Kontrola jakości jest integralną częścią każdego procesu produkcyjnego, bez względu na branżę. Spełnienie wysokich standardów w tej dziedzinie jest wyróżnikiem wśród konkurencji i ułatwia pozyskiwanie i przywiązywanie do siebie klientów. W niektórych gałęziach przemysłu jest też wymuszone przepisami, których spełnienie jest warunkiem koniecznym prowadzenia legalnej działalności i uzyskania zgody na wprowadzenie produktów do sprzedaży. Przykłady to branże: spożywcza, farmaceutyczna oraz chemiczna.
Kontrola jakości jest integralną częścią każdego procesu produkcyjnego, bez względu na branżę. Spełnienie wysokich standardów w tej dziedzinie jest wyróżnikiem wśród konkurencji i ułatwia pozyskiwanie i przywiązywanie do siebie klientów. W niektórych gałęziach przemysłu jest też wymuszone przepisami, których spełnienie jest warunkiem koniecznym prowadzenia legalnej działalności i uzyskania zgody na wprowadzenie produktów do sprzedaży. Przykłady to branże: spożywcza, farmaceutyczna oraz chemiczna.
W zależności od specyfiki produkcji, wyrobów lub możliwości realizacji kontrola jakości jest przeprowadzana na różnych etapach. Najbardziej opłacalne jest jak najwcześniejsze wykrycie produktów wybrakowanych, ogranicza to bowiem straty materiałów, energii i innych zasobów przedsiębiorstwa, które zostałyby zużyte do wyprodukowania wyrobów, które ostatecznie nie zostaną wprowadzone do sprzedaży. W tradycyjnym podejściu generalnie najbardziej liczy się jednak efekt końcowy, czyli niedopuszczenie do tego, żeby produkt słabej jakości trafił w ręce kupującego.
...I W PRZYSZŁOŚCI
W strategii predykcyjnej chodzi natomiast o to, aby wykryć oznaki, które świadczą o tym, że do pogorszenia jakości produktu może dojść, czyli żeby przewidzieć defekty, zanim jeszcze wystąpią. Pozwala to na bieżąco wprowadzać poprawki, które do nich nie dopuszczą. Dzięki temu predykcja zapewnia oszczędności, ograniczając liczbę wadliwych wyrobów i upraszczając "zwykłą" inspekcję, co z kolei ma pozytywny wpływ na wydajność produkcji.
Rozwiązania z tej dziedziny pozwalają również na dobór optymalnych pod względem jakości produktu końcowego ustawień maszyn, procedur, receptur w zależności od zmiennej specyfiki wyrobu lub warunków produkcji. Najlepiej założenia predykcyjnej kontroli jakości zilustrować przykładami jej możliwych zastosowań.
PRZEGLĄD ZASTOSOWAŃ PREDYKCJI W KONTROLI JAKOŚCI
Nieregularności na powierzchni blachy powstałe w procesie walcowania są zwykle wykrywane na stanowisku ich inspekcji albo niestety dopiero wtedy, gdy stają się widoczne po ich zamalowaniu albo polakierowaniu, ponieważ różnie odbijają światło. W metodzie predykcyjnej natomiast na podstawie analizy parametrów pracy walcarki zawczasu rozpoznawane są oznaki znaczącego zużycia rolek, które skutkowałoby ich nierównomiernym dociskaniem do blachy. W porę interweniując i wymieniając je na nowe, można temu zapobiec.
Kolejnym przykładem jest automatyzacja takich zadań, jak spawanie albo dokręcanie śrub. Nie jest łatwa, ponieważ trudno jest programowo odwzorować wiedzę i doświadczenie operatorów oraz ich zdolność do adaptowania się do zmieniających się warunków i rozpoznawania zależności między różnymi ustawieniami maszyn i uwzględniania ich wpływu na jakość, na przykład spawu albo dokręcenia śruby. Dzięki rozwiązaniom z zakresu predykcyjnej kontroli jakości możliwe jest przewidywanie w czasie rzeczywistym rezultatów na podstawie analizy kombinacji różnych wartości parametrów pracy maszyn, w tym przypadku spawarki albo wkrętarki, a następnie wybranie tych najlepszych w danych warunkach.
PROGNOZOWANA KONTROLA JAKOŚCI - PRZYKŁADÓW CD.
W obrabiarkach sterowanych numerycznie czynnikiem, który ma bardzo duży wpływ na występowanie niedokładności geometrycznych zniekształcających obrabiany przedmiot albo powodujących przekroczenie tolerancji jego wymiarów, są deformacje termiczne. Powstają one na skutek różnic temperatur w obrębie maszyny.
Te z kolei spowodowane są przede wszystkim silnym nagrzewaniem się wrzeciona z narzędziem, jak też styku narzędzie-przedmiot obróbki. W efekcie części obrabiarki na przemian rozszerzają się i kurczą, co zwiększa niedokładność pozycjonowania, wyrównywania, siły docisku i innych funkcji oraz parametrów tych maszyn.
Szacuje się, że deformacje cieplne w obrabiarkach CNC odpowiadają za od 40% do nawet 70% niedokładności geometrycznych, dlatego tak ważne jest znalezienie sposobu na ich zmniejszenie. Rozwiązania z zakresu predykcyjnej kontroli jakości wykazują w tym zakresie dużą skuteczność. Uzyskuje się ją dzięki kompensowaniu prognozowanych błędów termicznych przez korygowanie ustawień maszyn, w tym ścieżek ruchu narzędzi, na podstawie wyników pomiarów temperatury w różnych miejscach obrabiarki.
Inny przykład to zadania, jak m.in. produkcja betonu, w których na jakość wyrobu końcowego i zgodność jego parametrów z normami mają wpływ proporcje składników mieszanki surowców i sposób ich dozowania. Najlepszą recepturę tradycyjnie opracowuje się, opierając się na wynikach badań laboratoryjnych. Dzięki predykcyjnej kontroli jakości zadanie to może być realizowane "w locie", zapewniając znaczącą oszczędność czasu, a zatem większą wydajność.
Predykcyjne utrzymanie ruchu na lotnisku
Na przykład na pewnym niemieckim lotnisku dziennie ponad 100 ciężarówek przywozi je z jego magazynów do hangarów, przejeżdżając w tym celu drogą wewnętrzną i mostem. Każdy z tych pojazdów transportuje nawet kilkadziesiąt tysięcy litrów paliwa. W związku z tym nieustającym problemem było zużywanie się oraz uszkadzanie nawierzchni drogi oraz struktury mostu. Żeby zapewnić drożność trasy przewozu paliwa, okresowo należało kontrolować jej stan. W tym celu pobierano próbki nawierzchni i mostu, które były badane w laboratorium. Na tej podstawie oceniano stopień ich zużycia i decydowano o konieczności przeprowadzenia napraw. Metoda ta miała wiele wad. Przede wszystkim ze względu na inwazyjność była skomplikowana, a przez to czasochłonna. Poza tym pobieranie próbek zakłócało przejezdność trasy. Dlatego postanowiono wdrożyć inne rozwiązanie. Zdecydowano się na system predykcyjnego utrzymania ruchu. W celu jego realizacji w nawierzchnię drogi i podpory mostu wbudowano w sumie kilkadziesiąt czujników (w tym m.in. temperatury, korozji, wilgoci), których zadaniem jest wykrywanie wczesnych oznak zmęczenia materiału. Każdy sensor wyposażono w nadajnik, który przesyła wyniki pomiarów do centrali, gdzie są analizowane. W porę interweniując, zapobiega się poważnym uszkodzeniom struktur drogi i mostu. Oprócz tego wykrywając je wcześnie, zyskuje się na czasie, co pozwala na zaplanowanie konserwacji w takim terminie, który nie koliduje z czasem zajętości trasy. |
 Stan wewnętrznej infrastruktury drogowej (dróg dojazdowych, pasów startowych) w obrębie lotnisk ma bardzo duży wpływ na ciągłość i sprawność ich funkcjonowania, są bowiem wykorzystywane do realizacji zadań z zakresu obsługi pasażerów oraz samolotów. Jednym z bardziej obciążających jest transport paliwa.
Stan wewnętrznej infrastruktury drogowej (dróg dojazdowych, pasów startowych) w obrębie lotnisk ma bardzo duży wpływ na ciągłość i sprawność ich funkcjonowania, są bowiem wykorzystywane do realizacji zadań z zakresu obsługi pasażerów oraz samolotów. Jednym z bardziej obciążających jest transport paliwa.ALTERNATYWA DLA PREWENCJI I REAKCYJNOŚCI W UTRZYMANIU RUCHU
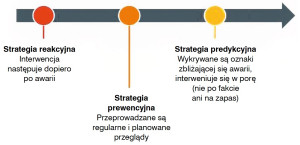
Podejście predykcyjne jest jedną ze strategii utrzymania ruchu. Polega na ciągłym monitorowaniu stanu urządzenia w celu natychmiastowego wykrycia ewentualnych niepokojących objawów. Jak tylko pojawią się pierwsze oznaki zbliżającej się awarii, ale zanim do niej dojdzie, podejmowana jest interwencja.
Jest to moment optymalny, gdyż działania nie są przeprowadzane na zapas, jak w przypadku metody prewencyjnej ani już po fakcie, jak w metodzie reakcyjnej, więc szkodom można zapobiec. W związku z tym predykcyjne utrzymanie ruchu ma wiele zalet w porównaniu z konkurencyjnymi strategiami w tej dziedzinie.
Dzięki temu, że praca urządzeń jest monitorowana bez konieczności ich wyłączania, zapobiega się niespodziewanym przestojom będącym wadą podejścia reakcyjnego i przerwom planowanym. Te drugie występują w czasie okresowych przeglądów prewencyjnych. Trudność sprawia dobór ich optymalnych odstępów - jeśli będą zbyt częste, mogą przynieść więcej strat niż oszczędności z powodu kosztownych przerw w produkcji i zaangażowania personelu. Zbyt rzadkie natomiast mijają się z celem, jeśli między przeglądami stan maszyn pogorszy się w takim stopniu, że się zepsują.
Jeżeli chodzi o wspólne zalety, predykcja i prewencja wydłużają żywotność urządzeń. Dodatkową korzyścią płynącą z ciągłego monitorowania pracy maszyn w razie archiwizowania pozyskanych w ten sposób danych jest możliwość stworzenia obszernej bazy wiedzy na ich temat. Informacje mogą się przydać w przyszłości w odniesieniu do nich albo innych podobnych.
PREDYKCYJNE UTRZYMANIE RUCHU W BRANŻY NAFTOWEJ
 Można mnożyć przykłady zastosowań predykcji w utrzymaniu ruchu w różnych gałęziach przemysłu. Jedną z branż, która dzięki wdrożeniu w dziedzinie utrzymania ruchu tej strategii uzyskuje szczególnie wiele korzyści, jest przemysł naftowy. Decyduje o tym specyfika instalacji wydobycia, przesyłu oraz przetwarzania ropy naftowej i gazu.
Można mnożyć przykłady zastosowań predykcji w utrzymaniu ruchu w różnych gałęziach przemysłu. Jedną z branż, która dzięki wdrożeniu w dziedzinie utrzymania ruchu tej strategii uzyskuje szczególnie wiele korzyści, jest przemysł naftowy. Decyduje o tym specyfika instalacji wydobycia, przesyłu oraz przetwarzania ropy naftowej i gazu.
Przede wszystkim awaria albo nieplanowany przestój krytycznych elementów wyposażenia w tego typu zakładach ze względu na rozmiary prowadzonej w nich produkcji skutkuje dużymi stratami finansowymi w związku z koniecznością przerwania produkcji albo transportu wyrobów. Jak na przykład oszacowała firma badawcza Kimberlite, nieplanowany przestój, który trwa zaledwie niecałe 4 dni, kosztuje operatorów morskich instalacji wydobycia ropy naftowej i gazu średnio przeszło 5 mln dol. Zakładając, że typowo rocznie przerwy w produkcji trwają ponad 25 dni, ich całkowity koszt przekracza 30 mln dol., a w najgorszych przypadkach nawet ponad 80 mln dol.
|
 Bogusław Krasuski
Bogusław KrasuskiWYCIEKI SĄ GROŹNE...
Awarie co gorsza mogą prowadzić do powstania wycieków surowców energetycznych. Dochodzi do nich również z powodu na przykład nieszczelności rurociągów.
Do wycieków w tej branży nie powinno się dopuszczać za wszelką cenę z wielu powodów. Jednym z ważniejszych jest troska o środowisko naturalne - na przykład wyciek do otoczenia ropy naftowej w dużej ilości w ciągu zaledwie kilku minut może skazić obszar objęty jego zasięgiem, niszcząc faunę i florę w takim stopniu, że powrót do stanu sprzed takiej katastrofy ekologicznej, o ile w ogóle będzie kiedykolwiek możliwy, trwać będzie dziesięciolecia.
Co gorsza, w przypadku wycieku surowców energetycznych groźne jest nie tylko ich toksyczne działanie bezpośrednie, ale także możliwość wybuchu i pożaru, jeszcze rozszerzających zasięg katastrofy. Poza otoczeniem, z powyższych powodów wycieki są także groźne dla personelu i wyposażenia zakładu.
|
 Jakub Kwiatkowski
Jakub Kwiatkowski...I DROGIE
Trzeba oprócz tego pamiętać o kosztach usunięcia ich skutków, w tym zaspokojenia roszczeń różnego typu. Przykładowo koncern BP na pokrycie wydatków biznesowych oraz odszkodowań za wyciek do Zatoki Meksykańskiej 130 mln baryłek ropy naftowej, który spowodował eksplozję i pożar na platformie wiertniczej Deepwater Horizon i zniszczenie 500 kilometrów wybrzeży USA, przeznaczył 65 mld dol. Chociaż do tego wypadku doszło w 2010 roku, od tego czasu koszty stale wzrastały aż do 2018 roku, kiedy to dopiero ostatecznie je podsumowano.
Doliczyć trzeba również koszty straconych surowców. Jak kilka lat temu oszacował "Forbes" globalnie średnio rocznie wartość gazu ziemnego, który wycieka do atmosfery w ilościach liczonych w bilionach metrów sześciennych, sięga nawet 30 mld dol.
PREDYKCJA JEST NAJLEPSZYM ROZWIĄZANIEM
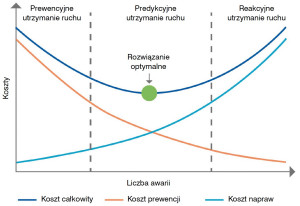
Z wyżej wymienionych powodów w zapobieganiu wyciekom w przemyśle naftowym podejście reakcyjne nie wchodzi w grę. Natomiast strategia prewencyjna, w której kontrole w kluczowych punktach zakładu muszą być przeprowadzane bardzo często, a nawet codziennie, jest czasochłonna, a przez to kosztowna.
Poza tym planowane przestoje nie są w zakładach w tej branży błahym przedsięwzięciem. Ze względu na stopień złożoności operacji, warunki, w jakich są realizowane, rozległość instalacji, liczbę urządzeń i ich wzajemne powiązania, wyłączenia prewencyjne wymagają zaangażowania dużych sił, środków i nierzadko miesięcy przygotowań. Strategia predykcyjna wydaje się zatem najlepszym rozwiązaniem.
Podobne wymagania oraz ograniczenia, jak w przemyśle naftowym, występują też m.in. w branży elektroenergetycznej, w przypadku której priorytetem jest utrzymanie ciągłości dostaw energii elektrycznej. Oprócz przemysłu podejście predykcyjne sprawdza się również w infrastrukturze, szczególnie w miejscach trudno dostępnych, jak drogi, mosty czy tory na kolei. Przykłady jego zastosowań w tej dziedzinie przedstawiamy w ramce.
POMIARY W PREDYKCYJNYM UTRZYMANIU RUCHU
W celu jak najwcześniejszego wykrycia problemów monitoruje się różne wielkości, których wartość, przebieg zmienności albo odchyłka od wartości typowych mogą wskazywać na jakieś nieprawidłowości. Wśród tych najczęściej mierzonych wymienić można: temperaturę, wibracje i wielkości elektryczne, w tym: natężenie prądu, napięcie, pobór mocy i parametry jakości energii elektrycznej oraz natężenie przepływu i ciśnienie, których spadek może świadczyć o wcześniej wspomnianych wyciekach. Zwiastunami zbliżającej się awarii mogą być poza tym: nadmierny hałas, dźwięki nietypowe oraz ultradźwięki.
Mierniki tych ostatnich są ważnym narzędziem diagnostycznym w przypadku łożysk. Są one newralgicznym elementem maszyn, dlatego do monitorowania ich stanu w predykcyjnym utrzymaniu ruchu przywiązuje się szczególnie dużą wagę.
Pomiary ultradźwięków, czyli fal dźwiękowych o częstotliwościach z zakresu powyżej progu słyszalności człowieka, pozwalają na wykrywanie problemów z łożyskami na bardzo wczesnym etapie ich rozwoju, nim jeszcze wystąpią inne ich oznaki, jak na przykład wzrost temperatury albo nadmierne wibracje. Do nieprawidłowości, które można w ten sposób rozpoznać, zalicza się m.in.: zużycie zmęczeniowe, wgniecenia na powierzchni bieżni (brinelling) oraz zbyt słabe smarowanie.
ULTRADŹWIĘKI W ŁOŻYSKACH
 Zużycie zmęczeniowe jest przyczyną powstawania odkształceń na powierzchniach elementów łożysk. Z powodu tych nieregularności ruchowi części tocznych po bieżni pierścieni towarzyszy emisja ultradźwięków. Miernik wykrywa zwiększenie się ich amplitudy za każdym razem, gdy na przykład kulka natrafia na nierówność na powierzchni rowka. Wzmocnienie ultradźwiękowego sygnału występuje także w przypadku drugiego z wymienionych defektów, czyli wgnieceń na powierzchni bieżni.
Zużycie zmęczeniowe jest przyczyną powstawania odkształceń na powierzchniach elementów łożysk. Z powodu tych nieregularności ruchowi części tocznych po bieżni pierścieni towarzyszy emisja ultradźwięków. Miernik wykrywa zwiększenie się ich amplitudy za każdym razem, gdy na przykład kulka natrafia na nierówność na powierzchni rowka. Wzmocnienie ultradźwiękowego sygnału występuje także w przypadku drugiego z wymienionych defektów, czyli wgnieceń na powierzchni bieżni.
Przy normalnym obciążeniu oraz idealnie gładkich powierzchniach elementów łożysk w miejscu ich styku nacisk rozkładałby się równomiernie i występowałoby odkształcenie elastyczne. W rzeczywistości nie można jednak całkiem wyeliminować drobnych nieregularności. Dlatego stosowane są smary, które amortyzują nierówny nacisk w miejscach występowania defektów powierzchniowych.
W razie gdy smaru jest za mało, kontaktowi nierównomierności elementów łożysk towarzyszyć będzie zwiększona emisja ultradźwięków. Ważne jest, by wykryć to jak najszybciej, ponieważ z czasem nieregularności występujące normalnie przekształcą się w większe bruzdy, skracając żywotność łożysk.
|
 Michał Ścibior
Michał ŚcibiorNOWE TECHNOLOGIE W STRATEGII PREDYKCYJNEJ
Aby wdrożyć podejście predykcyjne, oprócz opomiarowania monitorowanych obiektów trzeba mieć możliwość transmisji wyników odczytów z czujników. Stają się one przeważnie użyteczne dopiero po przeanalizowaniu, na przykład prześledzeniu zależności między nimi, wyszukaniu podobieństw, dopasowaniu do wzorca.
Nie jest to prostym zadaniem, szczególnie że przygotowanie prognozy wymaga wyciągnięcia wniosków o przyszłym stanie na podstawie aktualnych oraz ewentualnie archiwalnych informacji. Dlatego potrzebne są specjalne narzędzia analityczne.
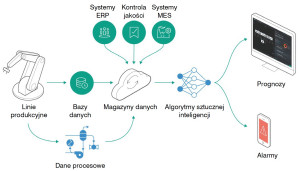
W typowym systemie predykcyjnym wyróżnia się zatem część sprzętową oraz część programową. Przewiduje się, że nowe technologie znacząco rozszerzą możliwości obu. Są potrzebne, ponieważ ilość danych do przetworzenia, wymagana szybkość analizy oraz stopień jej skomplikowania stale rosną. Tymczasem lokalne implementacje w oparciu o systemy SCADA, MES czy ERP i narzędzia analityczne bazujące na statystyce stopniowo osiągają kres swoich możliwości.
Wśród najbardziej obiecujących nowych technologii wymienia się tytułowy Internet Rzeczy, który wypełnia lukę między starszym sprzętem przemysłowym i infrastrukturą a takimi nowinkami, jak chmura obliczeniowa i techniki przetwarzania dużych zbiorów danych (Big Data) wykorzystujące sztuczną inteligencję. Stanowią one trzon koncepcji Przemysłu 4.0.
CZUJNIKI I KOMUNIKACJA W SIECIACH IOT
Na część sprzętową składają się czujniki i moduły komunikacyjne. W zakresie jej realizacji stosuje się różne podejścia. Coraz popularniejsze są smart sensory. Stanowią one zintegrowane jednostki zawierające element pomiarowy, blok wstępnego przetwarzania wyników pomiarów oraz nadajnik wysyłający odczyty do jednostki nadrzędnej. Są w nie wyposażane nowe urządzenia, które dzięki temu są fabrycznie przygotowane do podłączenia do sieci Internetu Rzeczy. Starsze natomiast wyposaża się w specjalne moduły pomiarowo-komunikacyjne.
W zakresie metod łączności dostępnych jest wiele rozwiązań. Podstawowa klasyfikacja wprowadza ich podział na przewodowe i bezprzewodowe. Zaletą drugich jest łatwość i przeważnie niższy koszt wdrożenia, dzięki możliwości zorganizowania sieci przy minimalnej ingerencji w otoczenie oraz jej doprowadzenia w miejsca trudno dostępne.
W zakresie typu sieci bezprzewodowej wybór jest szerszy. Coraz większą popularność zyskują na przykład sieci LPWAN (Low Power Wide Area Networks). Ich najważniejsze cechy to: duży zasięg transmisji (do kilku kilometrów), mała przepływność, niski pobór mocy i prostota obniżająca koszt realizacji. Są one pożądane m.in. w przypadku czujników zasilanych bateryjnie wbudowywanych na przykład w elementy infrastruktury, do których dostęp jest utrudniony. Przykładami sieci LPWAN są działające w nielicencjonowanym paśmie częstotliwości LoRa oraz SigFox.
Zdalny monitoring farmy wiatrowej
Do tej pory po burzy wysyłano zespół, który sprawdzał stan łopatek. Było to rozwiązanie wysoce nieefektywne, zapobiegawczo należało bowiem wyłączyć i skontrolować w danym obiekcie każdą turbinę, ponieważ nigdy nie było wiadomo, która została trafiona piorunem, a nawet czy do takiego zdarzenia w ogóle doszło. Ponoszono w związku z tym znaczące straty spowodowane przerwaniem produkcji energii elektrycznej. Aby usprawnić inspekcję zdecydowano się wdrożyć system zdalnego monitoringu. Z jego realizacją wiązało się poważne utrudnienie - ponieważ wirnik z łopatkami się obraca fizyczne podłączenie sensorów do gondoli nie wchodziło w grę. Zatem wyposażono je w baterie, a odczyty wyników pomiarów przesyłane są bezprzewodowo siecią LoRa. W momencie uderzenia pioruna sensory wykrywają wzrost natężenia prądu przepływającego przez łopatki. Informacja o tym, razem z danymi pozwalającymi zlokalizować turbinę oraz uszkodzoną łopatkę, jest transmitowana do stacji pomiarowej - na każdej farmie wiatrowej został zbudowany jeden tego typu obiekt. Ze stacji pomiarowej zbiorcze odczyty przesyłane są do chmury. Tam są gromadzone i analizowane wraz z innymi danymi. Oprócz wykrywania uderzenia pioruna czujniki bowiem rejestrują i cyklicznie wysyłają do stacji pomiarowej szereg innych parametrów, które pozwalają ocenić stan łopatek. Na ich podstawie w specjalnym oprogramowaniu w chmurze opracowywana jest prognoza o tym, kiedy struktura łopat ulegnie zużyciu w takim stopniu, że mogą się połamać. Pozwala to na efektywniejsze rozplanowanie prac konserwacyjnych. |
 Pewien duński operator kilku farm wiatrowych składających się w zależności od obiektu z od 10 do 15 turbin o łącznej mocy 20 MW rozmieszczonych na obszarze o powierzchni 2÷3 km² w różnych regionach kraju postanowił usprawnić inspekcję przeprowadzaną pod kątem wystąpienia uszkodzeń łopatek spowodowanych uderzeniem w nie pioruna. Sprawdzenia są konieczne, bo niewymienienie ich w porę może prowadzić do zniszczenia ich i wirnika.
Pewien duński operator kilku farm wiatrowych składających się w zależności od obiektu z od 10 do 15 turbin o łącznej mocy 20 MW rozmieszczonych na obszarze o powierzchni 2÷3 km² w różnych regionach kraju postanowił usprawnić inspekcję przeprowadzaną pod kątem wystąpienia uszkodzeń łopatek spowodowanych uderzeniem w nie pioruna. Sprawdzenia są konieczne, bo niewymienienie ich w porę może prowadzić do zniszczenia ich i wirnika.JAKIE CECHY SIECI SĄ ISTOTNE?
Z kolei operatorzy sieci komórkowych, wychodząc naprzeciw rosnącym potrzebom w dziedzinie Internetu Rzeczy, w tym jego przemysłowej wersji, rozwijają dwa nowe standardy sieci LPWAN. Są to: LTE-M, który wyróżnia szybkość transmisji (około 1 Mb/s), zasięg, możliwość transmisji głosu, energooszczędność (10 lat pracy urządzenia na jednej baterii) oraz Narrowband-IoT (NB-IoT).
Ten drugi zapewnia porównywalnie niskie zużycie energii, obsługę dużej liczby połączeń przypadających na jedną stację bazową i bardzo dobry zasięg w pomieszczeniach, w sieciach NB-IoT zagwarantowana jest bowiem łączność przy sygnale ze stacji bazowej na poziomie aż o 20 dB niższym niż w sieciach 2G.
Czujniki oprócz tego często pracują w sieciach ZigBee, które charakteryzuje: mały pobór energii, niewielkie przepływności (do 250 kb/s) i zasięg między węzłami do 100 metrów. Z kolei lokalne sieci Internetu Rzeczy, na przykład w obrębie fabryki, w których niskie zużycie energii ani duży zasięg nie są priorytetami, opierają się na standardzie Wi-Fi. W sieciach przewodowych natomiast dominuje Ethernet. Żeby wybrać najlepsze rozwiązanie, należy zestawić ze sobą cechy sieci oraz wymagania danego zastosowania.
Najważniejszymi z nich są: zasięg - na przykład krótki pozwala na terytorialne ograniczenie dostępu do sieci, co jest przydatne ze względów bezpieczeństwa, szybkość transmisji, ilość przesyłanych danych - należy unikać sytuacji, w których dane kontrolne zajmowałyby więcej miejsca w ramce niż główna informacja (na przykład wynik pomiaru), gdyż taka nieefektywność spowalnia transmisję i sytuacji odwrotnych, gdy dane trzeba dzielić na części przesyłane oddzielnie, co z kolei jest przyczyną opóźnień, bezpieczeństwo komunikacji, pobór mocy, interoperacyjność i skalowalność (możliwość powiększania sieci o kolejne węzły bez pogarszania się dotychczasowej jakości transmisji).
CZYM JEST BIG DATA?
Jak wspomnieliśmy wcześniej, prognozowanie wymaga dostępu do informacji różnego typu. Oprócz danych pozyskanych z czujników monitorujących bieżącą aktywność obiektu inspekcji potrzebne są informacje o nim, w tym m.in. specyfikacja modelu urządzenia oraz jego aktualne ustawienia, dane archiwalne o tym, jak było użytkowane na przestrzeni czasu, w tym też o tym, jakim czynnościom konserwacyjnym oraz naprawom było poddawane. Źródłem danych są również różne systemy informatyczne, z których korzysta się w danym zakładzie (ERP, MES, itp.).
Upowszechnianie się Internetu Rzeczy sprawia, że informacji do przetworzenia będzie przybywać. Dane pozyskiwane tą drogą są jednak specyficzne - ich zbiory oprócz ogromnych rozmiarów, dużej szybkości napływu, która może dodatkowo podlegać okresowym wahaniom oraz dużej oczekiwanej szybkości ich przetwarzania, charakteryzuje również różnorodność źródeł oraz formatów.
Wszystko to utrudnia ich analizę, a trzeba pamiętać, że rzeczywista wartość informacji nie zależy od tego, w jakiej ilości uda się je zebrać, lecz od tego, w jakim stopniu zostaną wykorzystane.
Im więcej jest danych, tym jednak trudniejsze jest rozpoznanie wśród nich tych użytecznych, czyli oddzielenie treści od szumów. Następnie należy jeszcze informacje te ze sobą pokojarzyć, tzn. określić relacje, hierarchię oraz różnorodne inne powiązania, które między nimi występują i na tej podstawie wyciągnąć wnioski na temat prawdopodobieństwa różnych przyszłych zdarzeń.
AI? ML? DL?
 W realizacji tych zadań coraz lepiej sprawdza się sztuczna inteligencja (Artificial Intelligence, AI). Chociaż trudno w to uwierzyć, biorąc pod uwagę fakt, że przez wiele lat był to termin wyłącznie z pogranicza literatury i filmów science fiction oraz akademickich rozważań, dziedzina ta zaczyna dostarczać coraz skuteczniejszych technik, które pozwalają rozwiązywać problemy z zakresu analizy danych do tej pory trudne do rozstrzygnięcia, a nawet nierozwiązywalne.
W realizacji tych zadań coraz lepiej sprawdza się sztuczna inteligencja (Artificial Intelligence, AI). Chociaż trudno w to uwierzyć, biorąc pod uwagę fakt, że przez wiele lat był to termin wyłącznie z pogranicza literatury i filmów science fiction oraz akademickich rozważań, dziedzina ta zaczyna dostarczać coraz skuteczniejszych technik, które pozwalają rozwiązywać problemy z zakresu analizy danych do tej pory trudne do rozstrzygnięcia, a nawet nierozwiązywalne.
Jedną z tych metod jest uczenie maszynowe (Machine Learning, ML) i jego podgrupa - uczenie głębokie (Deep Learning, DL), które wykorzystuje sieci neuronowe. Według definicji ML jest to zdolność komputerów do uczenia się bez programowania im nowych umiejętności wprost.
Opiera się ono na algorytmach, które analizując dostarczane im dane, wyciągają wnioski i uczą się z nich, by następnie zdobytą w ten sposób wiedzę wykorzystać w podejmowaniu decyzji potrzebnych do rozwiązania konkretnych problemów. Co więcej, z czasem, w miarę, jak przetwarzają coraz więcej danych, samodoskonalą się bez konieczności ich przeprogramowywania.
UCZENIE NADZOROWANE I NIENADZOROWANE
W przypadku zaimplementowania uczenia maszynowego w oprogramowaniu wykorzystywanym w predykcyjnym utrzymaniu ruchu albo predykcyjnej kontroli jakości w praktyce oznacza to, że będzie się ono uczyło "normalnego zachowania" maszyny, aby następnie móc spożytkować tę wiedzę do identyfikacji oznak możliwych odchyleń od normy i ostrzegania o nich.
Do kategorii uczenia maszynowego zaliczanych jest wiele algorytmów. Różne są też sposoby ich klasyfikacji. Przykładowo dzieli się je na uczenie nadzorowane oraz nienadzorowane. Algorytmy zaliczane do pierwszej grupy operują na danych opisanych, między którymi poszukują zależności, żeby osiągnąć jasno określony cel.
W przypadku algorytmów drugiej kategorii natomiast ani dane wejściowe nie są opisane, ani oczekiwany wynik końcowy nie jest sprecyzowany, zaś zadaniem jest pogrupowanie danych wejściowych albo przeanalizowanie ich struktury w celu wychwycenia jakichś zależności.
KLASYFIKACJA A REGRESJA
Przykładem algorytmów, które należy zaliczyć do pierwszego zbioru, są algorytmy klasyfikacyjne. To je m.in. implementuje się w oprogramowaniu wykorzystywanym w predykcyjnym utrzymaniu ruchu i predykcyjnej kontroli jakości. Przykładami ich zastosowań w życiu codziennym są filtry antyspamowe w poczcie elektronicznej i badania zdolności kredytowej klientów banku, którzy starają się o kredyt.
Na ich podstawie można się dość łatwo domyślić sposobu, w jaki działają algorytmy klasyfikacyjne. Polega on (w bardzo dużym uproszczeniu) na tym, żeby znaleźć na postawione pytanie jednoznaczną odpowiedź poprzez wybór jednej z możliwych opcji (tak / nie albo A / B / C / D).
Do kategorii uczenia nadzorowanego należy również zaliczyć algorytmy regresyjne. O ile w tych klasyfikacyjnych poszukiwana była odpowiedź binarna (0 / 1, tak / nie), o tyle w przypadku regresyjnych prognozowana jest wartość numeryczna. Przykładem ich zastosowania w życiu codziennym jest przewidywanie wielkości sprzedaży albo wartości zysku. Z algorytmów regresyjnych również korzysta się w predykcyjnym utrzymaniu ruchu i predykcyjnej kontroli jakości.
CZYM JEST CHMURA?
Wymagania, jakie pod względem mocy obliczeniowej oraz pamięci niesie ze sobą gromadzenie dużych ilości danych i implementacja algorytmów uczenia maszynowego zwykle przekraczają możliwości typowej infrastruktury informatycznej, jaką dysponują niewyspecjalizowane w tej dziedzinie przedsiębiorstwa. By zatem Internet Rzeczy, a za nim techniki sztucznej inteligencji, mogły trafić pod strzechy musiała się pojawić możliwość przerzucenia obciążeń, które z nich wynikają, na innych.
Stworzyła ją chmura obliczeniowa (Cloud Computing). Jest to usługa polegająca na dostarczaniu zasobów informatycznych, na przykład serwerów, baz danych, sieci, oprogramowania, z których można korzystać za pośrednictwem Internetu. Rozwiązanie to zyskuje coraz większą popularność dzięki swoim licznym zaletom.
Predykcyjne utrzymanie w transporcie szynowym
Uzasadniano to planowanym zwiększeniem wydobycia, przez co skład wydłużyłby się o kolejne wagony i wzrosłaby częstość przejazdów pociągów. Obawiano się, że wzmożone natężenie ruchu oraz większe obciążenie będą powodować na tej linii problemy eksploatacyjne. Zrealizowany system opiera się na zdalnym monitoringu za pośrednictwem rozlokowanych na trasie przejazdu pociągu sensorów. Uznano to za skuteczniejszy, a w dłuższej perspektywie też tańszy sposób, niż okresowe sprawdzanie stanu szyn i prewencyjną wymianę kół. Jego częścią jest podsystem kontroli kształtu kół. Z czasem na skutek zużywania się materiału powodującego pęknięcia, ubytki i spłaszczenia ulega on zmianie, wpływając na dynamikę oraz stabilność pojazdu, a przez to na bezpieczeństwo jazdy (prawdopodobieństwo wykolejenia), jej komfort i stan torów. Co ważne zwykle z każdej strony koła są zdeformowane w innym stopniu. Dlatego z obu stron każdej z szyn zamontowano stację pomiarową. Zawiera ona źródło światła, kamerę oraz nadajnik. Jeżeli na torach nie ma pociągu skrzynki są osłonięte ochronną obudową. Kilkaset metrów przed nimi w torowisko wbudowano czujnik, który wykrywa obecność pojazdu. Wtedy automatycznie pokrywa na skrzynkach się unosi i włącza się światło, a kamera fotografuje kolejne koła. Zdjęcia są wysyłane do operatora linii kolejowej, gdzie są analizowane w programie przetwarzającym obrazy. Każdy moduł pomiarowy jest także wyposażony w element grzejny, co pozwala na pracę nawet w ekstremalnie niskich temperaturach. Uzupełnieniem jest system ostrzegania o możliwości uszkodzenia torów. Opiera się on na analizie wyników pomiarów z czujników tensometrycznych mierzących naprężenia w szynach powstające pod wpływem nacisku pojazdu. Ich nieprawidłowy rozkład wskazuje na zdeformowany profil kół. Tensometry są przyspawane do szyjki szyny, do każdej po jednym, w kilku miejscach na torach. |
 Pewna szwedzka kopalnia do przewozu urobku wykorzystuje odcinek linii kolejowej. Z powodu bardzo długiego okresu eksploatacji, do 1895 roku w transporcie pasażerskim, a od 1985 roku w przewozach towarowych wymagała ona modernizacji. Poza poprawą ogólnego stanu torów oraz innymi naprawami przy okazji postanowiono wdrożyć system predykcyjnego utrzymania ruchu.
Pewna szwedzka kopalnia do przewozu urobku wykorzystuje odcinek linii kolejowej. Z powodu bardzo długiego okresu eksploatacji, do 1895 roku w transporcie pasażerskim, a od 1985 roku w przewozach towarowych wymagała ona modernizacji. Poza poprawą ogólnego stanu torów oraz innymi naprawami przy okazji postanowiono wdrożyć system predykcyjnego utrzymania ruchu.JAKIE SĄ KORZYŚCI Z CHMURY?
Przede wszystkim korzystając z chmury obliczeniowej, nie ponosi się wydatków inwestycyjnych związanych z zakupem sprzętu i oprogramowania ani później kosztów jego obsługi i utrzymania (wynagrodzenia specjalistów, opłaty za energię elektryczną zużywaną do zasilania i chłodzenia serwerów). Ponieważ zwykle usługi w ramach chmury są udostępniane na żądanie, ich klienci zyskują dużą swobodę - korzystają z potrzebnych zasobów kiedy chcą, bez konieczności wcześniejszego zaplanowania.
Dotyczy to także skali, w jakiej ich używają, co oznacza, że stosownie do potrzeb (i możliwości finansowych, jako że usługi w chmurze są płatne) mogą korzystać z większej mocy obliczeniowej, pamięci, przepustowości. Ponieważ to usługodawcy dbają o stronę sprzętowo-programową, a w ich interesie jest, by zapewnić użytkownikom usługi najwyższej jakości, klient zawsze uzyskuje dostęp do najnowszych rozwiązań, na bieżąco aktualizowanych i unowocześnianych. Dotyczy to również zabezpieczeń.
PODSUMOWANIE

Mimo generalnie pozytywnych prognoz dotyczących przyszłości Internetu Rzeczy i innych nowych technologii w predykcyjnym utrzymaniu ruchu oraz predykcyjnej kontroli jakości kilka czynników wciąż hamuje postęp w tych dziedzinach. Najważniejsze z nich są obawy o cyberbezpieczeństwo, które stale rosną, im więcej się mówi o zagrożeniach oraz potencjalnych skutkach ataków, które przeprowadzone za pośrednictwem infrastruktury informatycznej mogą wpłynąć na działanie tej fizycznej.
Kolejnym powodem do zmartwień są trudności w integracji technologii operacyjnej (OT) i technologii informatycznej (IT) oraz problemy, jakie występują na styku tych dwóch dziedzin. Hamulcem jest też nieprzekonanie o opłacalności.
O ile to ostatnie z pewnością będzie słabnąć, im więcej będzie się pojawiać dowodów na to, że można zyskać na inwestycji w IoT, niemniej jednak przed dostawcami rozwiązań w tym zakresie wciąż jeszcze wiele pracy, żeby przekonać wahających się o przewadze ich korzyści nad wadami.
Monika Jaworowska

























