
Sztuczna inteligencja a IIoT

Komponent analityczny jest jedną z kluczowych części platformy do zarządzania danymi IIoT. Analiza tego typu dużych zbiorów danych wymaga specjalnego podejścia oraz zaawansowanych rozwiązań. Ostatnio w tym zastosowaniu popularność zyskują algorytmy sztucznej inteligencji. Pozwalają one na opracowywanie modeli systemów, które inaczej niż tradycyjne, oparte na fizyce, charakteryzują ich działanie na podstawie danych.
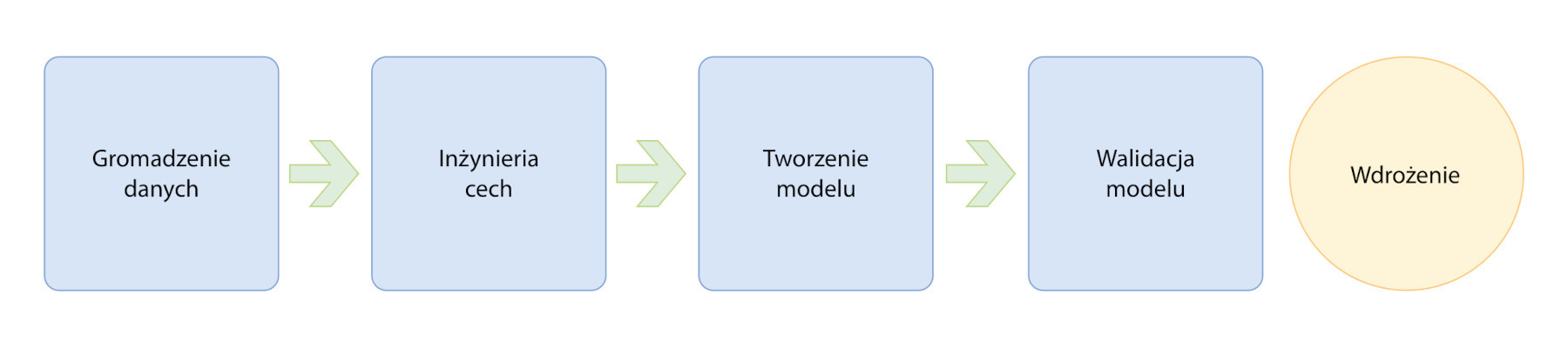
Przykładowo podzbiór technik sztucznej inteligencji, uczenie maszynowe (machine learning, ML), umożliwia w dziedzinie utrzymania ruchu przejście z konserwacji reaktywnej i zapobiegawczej do predykcyjnej – rozwiązania oparte na ML są już wykorzystywane nie tylko do detekcji nietypowego działania maszyn, diagnozowania problemów, ale również do pewnego stopnia do przewidywania pozostałego czasu ich użytkowania. Na rysunku 2 przedstawiamy ogólne etapy przygotowywania modelu ML, a na rysunku 3 jak wygląda to w praktyce na przykładzie opracowywania modelu do monitorowania pracy silnika. Dane są zbierane z wielu typów czujników, takich jak akcelerometry, termopary i przetworniki prądu zainstalowane w silniku. Etap inżynierii cech zwykle składa się z dwóch faz: ekstrakcji cech i redukcji cech.
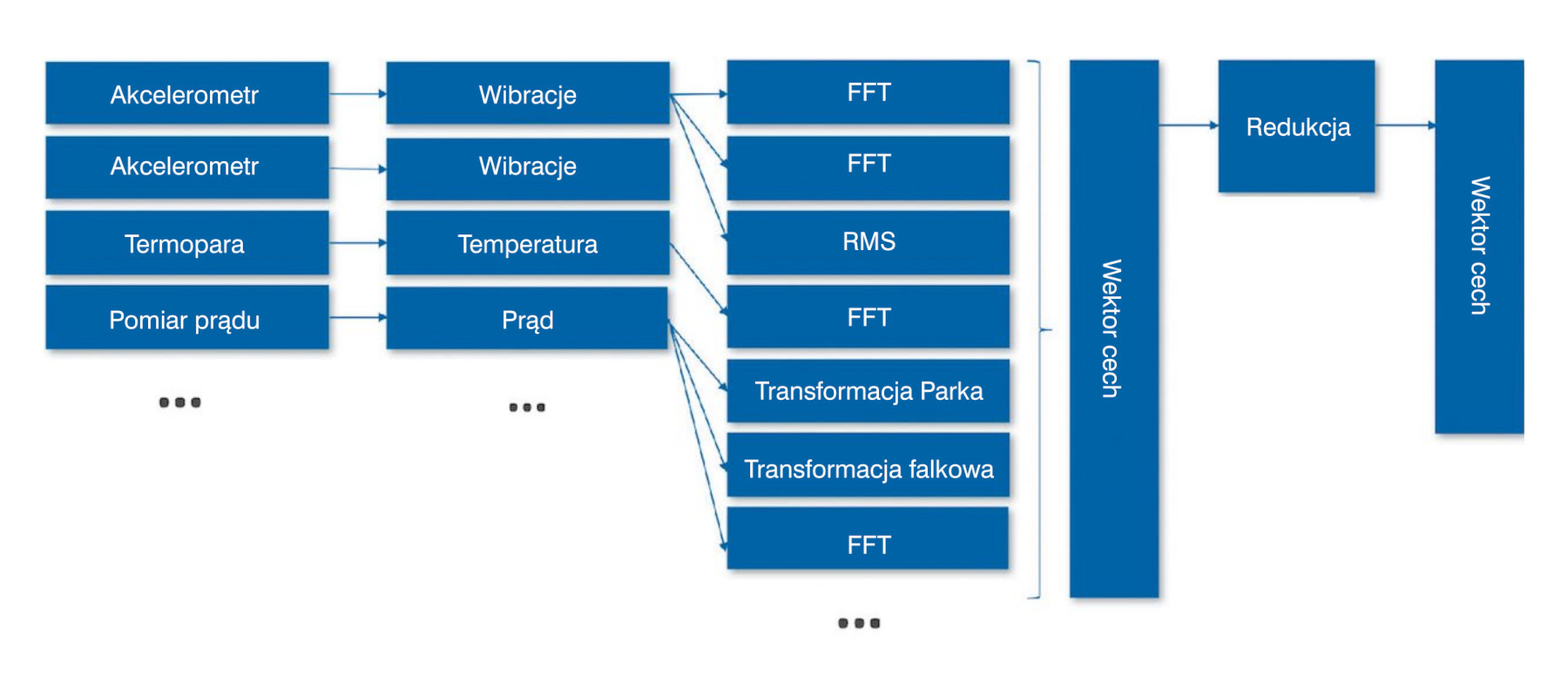
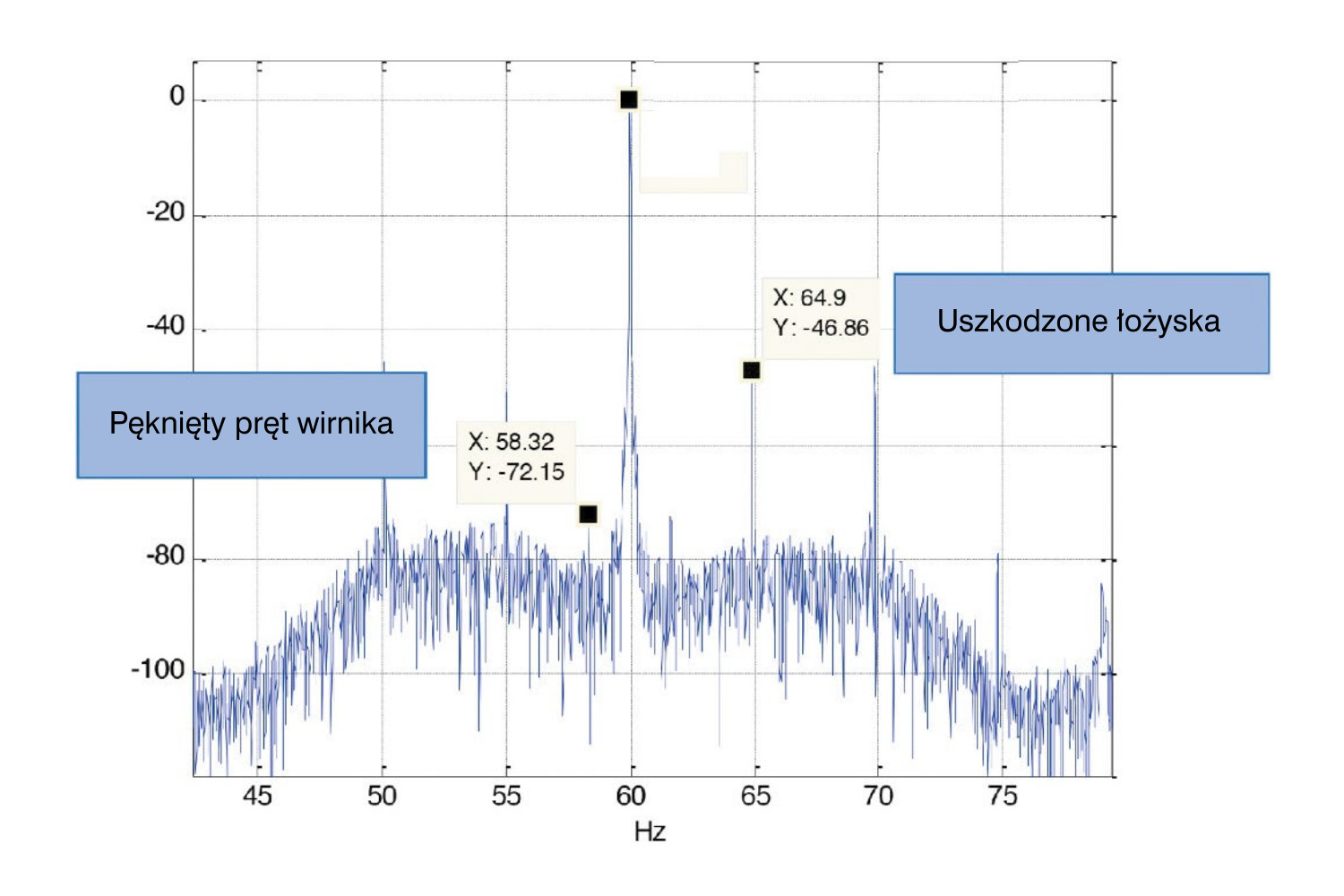
Pierwsza ma na celu wyodrębnienie przydatnych informacji z surowych danych, które pozwolą na określenie stanu urządzenia. Przykładowo niektóre składowe częstotliwościowe w widmie prądów fazowych silnika wskazują na konkretne problemy (rys. 4), za cechę można zatem przyjąć średnią amplitudę sygnału na takim wykresie. Ponieważ wyróżniki wyodrębnione na podstawie danych z wielu czujników mogą zawierać nadmiarowe informacje, konieczny jest etap redukcji, który ma na celu zmniejszenie liczby cech ostatecznie wykorzystywanych do zbudowania modelu. Im jest ich mniej, tym jest on prostszy. Zredukowany zestaw cech jest reprezentowany jako wektor (lub tablica) i wprowadzany do algorytmu. Tworzenie i sprawdzanie poprawności modelu to iteracyjny proces, w ramach którego eksperymentuje się z wieloma algorytmami i ostatecznie wybiera ten, który sprawdzi się najlepiej.
Uczenie nadzorowane i nienadzorowane
W dziedzinie uczenia maszynowego wyróżnia się dwie grupy algorytmów: uczenia nadzorowanego i nienadzorowanego. Te drugie sprawdzają się w poszukiwaniu ukrytych wzorców w danych bez konieczności ich etykietowania – pozwalają przykładowo zamodelować normalne działanie silnika i wykrywać, kiedy jego praca zaczyna odbiegać od normy.
Algorytmy uczenia nadzorowanego są wymagane do wykrywania przyczyn anomalii. Metody tego typu bazują na parach: danych wejściowych i pożądanym wyjściu. Pozwala to algorytmowi uczyć się funkcji, która odwzorowuje wejścia na wyjścia. W opisywanym przypadku dane używane do trenowania algorytmu ML tego typu obejmują cechy wyodrębnione w warunkach normalnych i podczas awarii silnika. Są one wyraźnie określone za pomocą etykiety, która oznacza stan silnika.
Wyzwaniem związanym z tradycyjnymi technikami uczenia maszynowego jest proces ekstrakcji cech. Etap ten eliminuje się w obecnie jednej z szybciej rozwijających się dziedzin ML – uczeniu głębokim (deep learning, DL). Dane pozyskane z czujników (surowe pomiary) można w tym przypadku bezpośrednio wprowadzić do algorytmów DL (rys. 5).



















