
Czym jest deep learning?

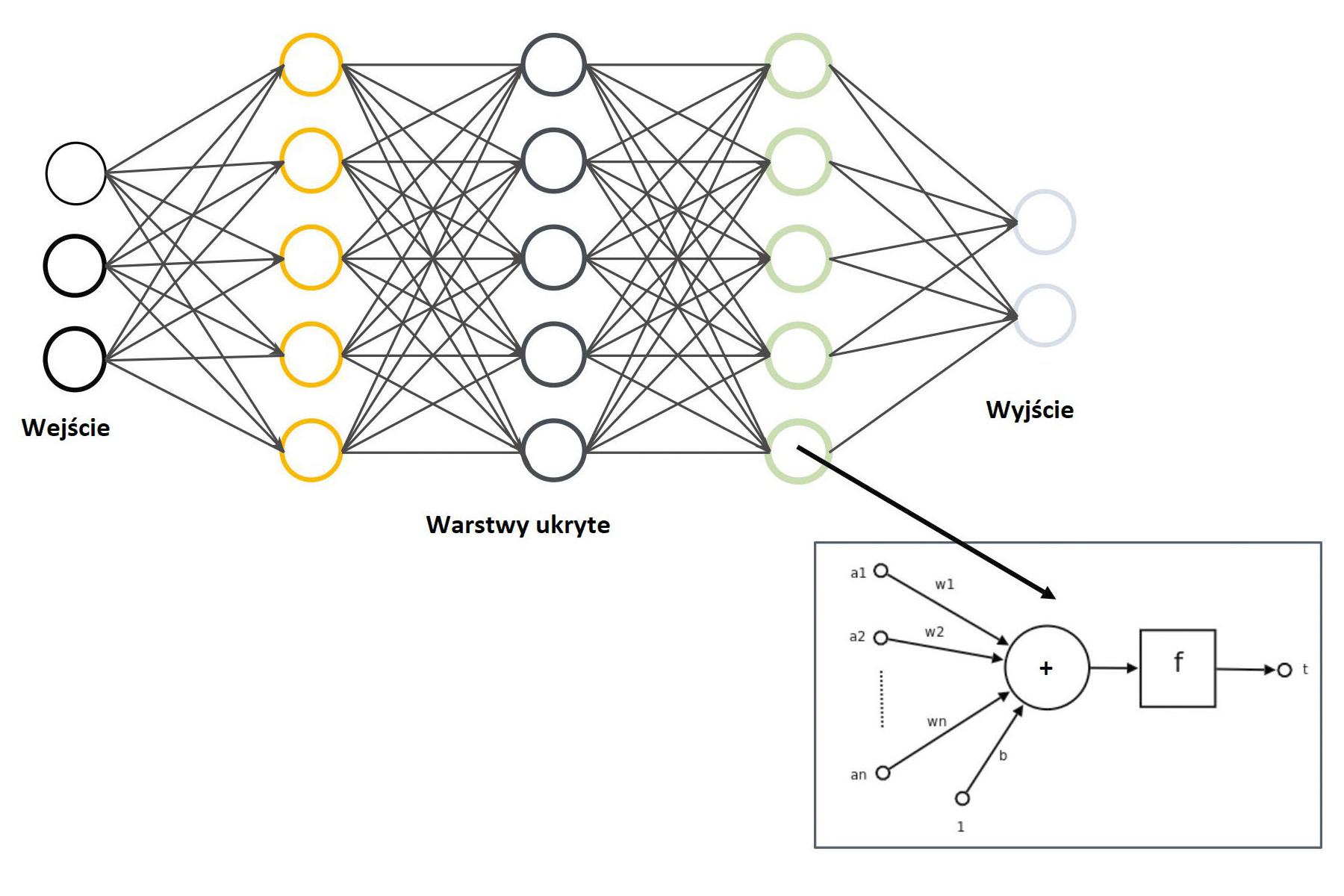
DL oparte jest na sztucznych sieciach neuronowych, których algorytmy uczenia się są inspirowane strukturą i działaniem biologicznych sieci neuronowych. Algorytmy te mają strukturę połączonych ze sobą grup węzłów obliczeniowych (sztucznych neuronów), które są zorganizowane w warstwy. Pierwsza z nich jest określana jako warstwa wejściowa, która łączy się z sygnałem wejściowym lub danymi. Ostatnia warstwa to warstwa wyjściowa, a neurony w tej warstwie wysyłają ostateczną prognozę albo decyzję. Pomiędzy warstwą wejściową a wyjściową znajduje się jedna lub więcej warstw ukrytych (rys. 6). Wyjścia jednej warstwy są połączone z węzłami w następnej warstwie za pomocą połączeń ważonych. Sieć neuronowa uczy się mapowania zależności między wejściem a wyjściem, modyfikując te wagi. Wykorzystując wiele warstw ukrytych, algorytmy DL uczą się cech, które należy wyodrębnić z danych wejściowych, bez konieczności ich bezpośredniego wprowadzania do algorytmu uczącego się.
Przyszłościowe techniki DL
DL szybko się rozwija. Opracowywane są w związku z tym różne topologie, spośród których kilka wyróżnia się potencjałem w obróbce danych IIoT. Przykładem są głębokie sieci neuronowe (Deep neural network, DNN), czyli w pełni połączone sztuczne sieci neuronowe z wieloma ukrytymi warstwami. Warte uwagi są także konwolucyjne sieci neuronowe (Convolutional Neural Network, CNN), składające się z jednej lub więcej warstw konwolucyjnych (warstw filtrujących), po których następuje w pełni połączona wielowarstwowa sieć neuronowa. Kolejnym przykładem są RNN (Recurrent Neural Network), oparte na algorytmach, które wykorzystują informacje sekwencyjne (lub historyczne) do prognozowania. Tradycyjne sieci neuronowe zakładają, że wszystkie wejścia (i wyjścia) są od siebie niezależne pod względem czasu lub kolejności nadejścia, RNN natomiast przechowują informacje o przeszłości i wykorzystują je do następnej prognozy. Kluczowe znaczenie w przyszłości będzie też z pewnością miała technika DRL (Deep Reinforcement Learning), czyli głębokiego uczenia przez wzmacnianie, którego potencjał dostrzeżono już na przykład w projektowaniu adaptacyjnych systemów sterowania działających w złożonym, dynamicznym otoczeniu.
Podsumowanie
Głębokie sieci neuronowe wymagają dużych ilości danych treningowych, które najlepiej by obejmowały informacje ze wszystkich możliwych stanów albo warunków, których sieć musi się nauczyć. Źródłem takich jest z pewnością Przemysłowy Internet Rzeczy. Z drugiej strony ogromne ilości danych w sieciach IIoT bez AI nie będą tak użyteczne, jak mogą być po poddaniu analizie za pomocą algorytmów sztucznej inteligencji. W związku z tym z pewnością w kolejnych latach będzie można zaobserwować, jak obie te technologie się uzupełniają, napędzając wzajemnie swój rozwój.
Monika Jaworowska

















